
Kylin v2.0 introduces the Spark cube engine, it uses Apache Spark to replace MapReduce in the build cube step; You can check this blog for an overall picture. The current document uses the sample cube to demo how to try the new engine.
Preparation
To finish this tutorial, you need a Hadoop environment which has Kylin v2.1.0 or above installed. Here we will use Hortonworks HDP 2.4 Sandbox VM, the Hadoop components as well as Hive/HBase has already been started.
Install Kylin v2.4.0 or above
Download the Kylin binary for HBase 1.x from Kylin’s download page, and then uncompress the tar ball into /usr/local/ folder:
wget http://www-us.apache.org/dist/kylin/apache-kylin-2.4.0/apache-kylin-2.4.0-bin-hbase1x.tar.gz -P /tmp
tar -zxvf /tmp/apache-kylin-2.4.0-bin-hbase1x.tar.gz -C /usr/local/
export KYLIN_HOME=/usr/local/apache-kylin-2.4.0-bin-hbase1xPrepare “kylin.env.hadoop-conf-dir”
To run Spark on Yarn, need specify HADOOP_CONF_DIR environment variable, which is the directory that contains the (client side) configuration files for Hadoop. In many Hadoop distributions the directory is “/etc/hadoop/conf”; Kylin can automatically detect this folder from Hadoop configuration, so by default you don’t need to set this property. If your configuration files are not in default folder, please set this property explicitly.
Check Spark configuration
Kylin embedes a Spark binary (v2.1.0) in $KYLIN_HOME/spark, all the Spark configurations can be managed in $KYLIN_HOME/conf/kylin.properties with prefix “kylin.engine.spark-conf.”. These properties will be extracted and applied when runs submit Spark job; E.g, if you configure “kylin.engine.spark-conf.spark.executor.memory=4G”, Kylin will use “–conf spark.executor.memory=4G” as parameter when execute “spark-submit”.
Before you run Spark cubing, suggest take a look on these configurations and do customization according to your cluster. Below is the recommended configurations:
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=1
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1000
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.yarn.queue=default
kylin.engine.spark-conf.spark.driver.memory=2G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
kylin.engine.spark-conf.spark.executor.cores=1
kylin.engine.spark-conf.spark.network.timeout=600
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
#kylin.engine.spark-conf.spark.executor.instances=1
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.hadoop.dfs.replication=2
kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress=true
kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
kylin.engine.spark-conf.spark.eventLog.dir=hdfs\:///kylin/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs\:///kylin/spark-history
## uncomment for HDP
#kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current
#kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current
#kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=currentFor running on Hortonworks platform, need specify “hdp.version” as Java options for Yarn containers, so please uncommment the last three lines in kylin.properties.
Besides, in order to avoid repeatedly uploading Spark jars to Yarn, you can manually do that once, and then configure the jar’s HDFS location; Please note, the HDFS location need be full qualified name.
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ .
hadoop fs -mkdir -p /kylin/spark/
hadoop fs -put spark-libs.jar /kylin/spark/After do that, the config in kylin.properties will be:
kylin.engine.spark-conf.spark.yarn.archive=hdfs://sandbox.hortonworks.com:8020/kylin/spark/spark-libs.jar
kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current
kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current
kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=currentAll the “kylin.engine.spark-conf.*” parameters can be overwritten at Cube or Project level, this gives more flexibility to the user.
Create and modify sample cube
Run the sample.sh to create the sample cube, and then start Kylin server:
$KYLIN_HOME/bin/sample.sh
$KYLIN_HOME/bin/kylin.sh startAfter Kylin is started, access Kylin web, edit the “kylin_sales” cube, in the “Advanced Setting” page, change the “Cube Engine” from “MapReduce” to “Spark”:

Click “Next” to the “Configuration Overwrites” page, click “+Property” to add property “kylin.engine.spark.rdd-partition-cut-mb” with value “500” (reasons below):

The sample cube has two memory hungry measures: a “COUNT DISTINCT” and a “TOPN(100)”; Their size estimation can be inaccurate when the source data is small: the estimized size is much larger than the real size, that causes much more RDD partitions be splitted, which slows down the build. Here 100 is a more reasonable number for it. Click “Next” and “Save” to save the cube.
Build Cube with Spark
Click “Build”, select current date as the build end date. Kylin generates a build job in the “Monitor” page, in which the 7th step is the Spark cubing. The job engine starts to execute the steps in sequence.

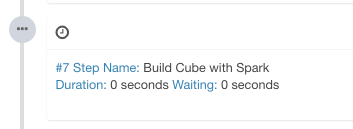
When Kylin executes this step, you can monitor the status in Yarn resource manager. Click the “Application Master” link will open Spark web UI, it shows the progress of each stage and the detailed information.
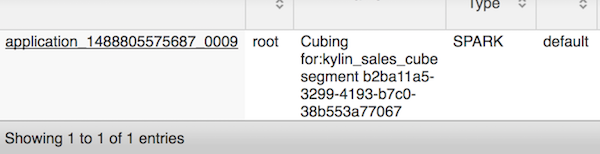
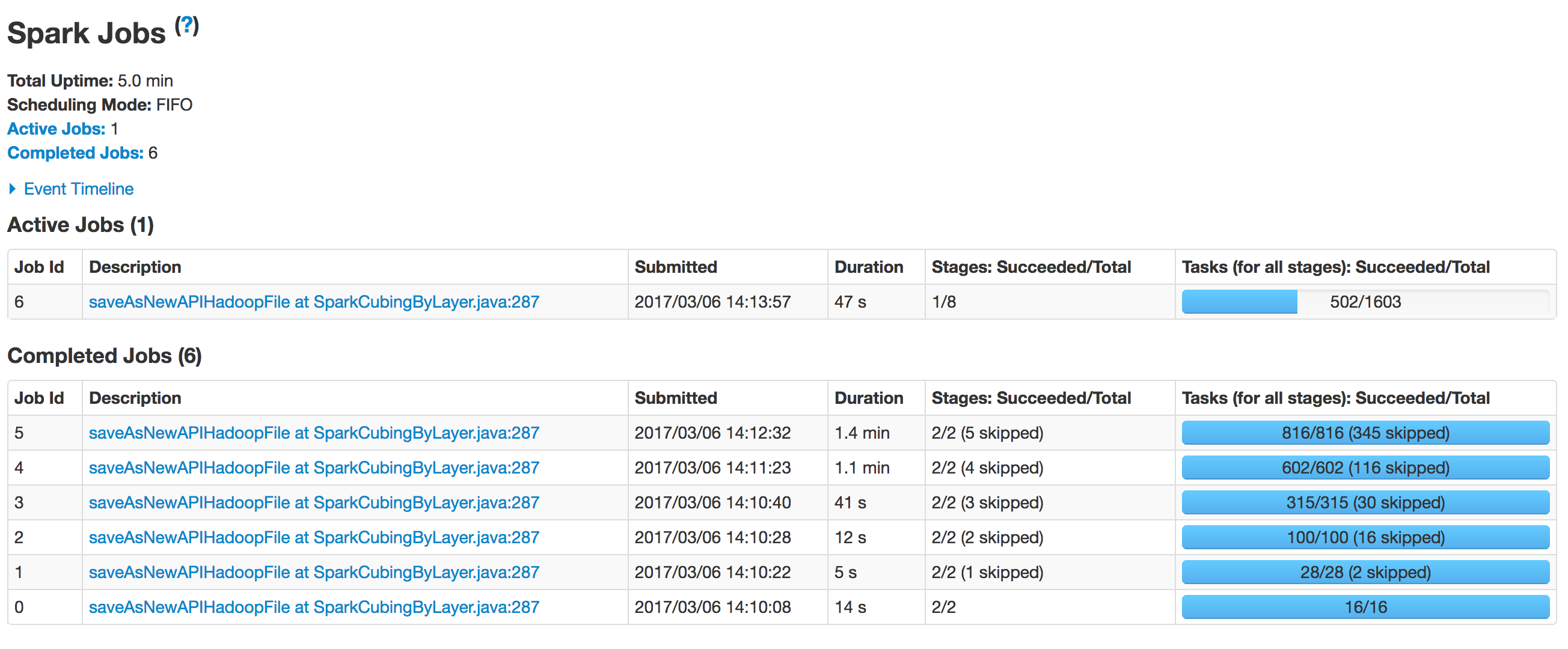
After all steps be successfully executed, the Cube becomes “Ready” and you can query it as normal.
Troubleshooting
When getting error, you should check “logs/kylin.log” firstly. There has the full Spark command that Kylin executes, e.g:
2017-03-06 14:44:38,574 INFO [Job 2d5c1178-c6f6-4b50-8937-8e5e3b39227e-306] spark.SparkExecutable:121 : cmd:export HADOOP_CONF_DIR=/etc/hadoop/conf && /usr/local/apache-kylin-2.4.0-bin-hbase1x/spark/bin/spark-submit --class org.apache.kylin.common.util.SparkEntry --conf spark.executor.instances=1 --conf spark.yarn.queue=default --conf spark.yarn.am.extraJavaOptions=-Dhdp.version=current --conf spark.history.fs.logDirectory=hdfs:///kylin/spark-history --conf spark.driver.extraJavaOptions=-Dhdp.version=current --conf spark.master=yarn --conf spark.executor.extraJavaOptions=-Dhdp.version=current --conf spark.executor.memory=1G --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs:///kylin/spark-history --conf spark.executor.cores=2 --conf spark.submit.deployMode=cluster --files /etc/hbase/2.4.0.0-169/0/hbase-site.xml /usr/local/apache-kylin-2.4.0-bin-hbase1x/lib/kylin-job-2.4.0.jar -className org.apache.kylin.engine.spark.SparkCubingByLayer -hiveTable kylin_intermediate_kylin_sales_cube_555c4d32_40bb_457d_909a_1bb017bf2d9e -segmentId 555c4d32-40bb-457d-909a-1bb017bf2d9e -confPath /usr/local/apache-kylin-2.4.0-bin-hbase1x/conf -output hdfs:///kylin/kylin_metadata/kylin-2d5c1178-c6f6-4b50-8937-8e5e3b39227e/kylin_sales_cube/cuboid/ -cubename kylin_sales_cubeYou can copy the cmd to execute manually in shell and then tunning the parameters quickly; During the execution, you can access Yarn resource manager to check more. If the job has already finished, you can check the history info in Spark history server.
By default Kylin outputs the history to “hdfs:///kylin/spark-history”, you need start Spark history server on that directory, or change to use your existing Spark history server’s event directory in conf/kylin.properties with parameter “kylin.engine.spark-conf.spark.eventLog.dir” and “kylin.engine.spark-conf.spark.history.fs.logDirectory”.
The following command will start a Spark history server instance on Kylin’s output directory, before run it making sure you have stopped the existing Spark history server in sandbox:
$KYLIN_HOME/spark/sbin/start-history-server.sh hdfs://sandbox.hortonworks.com:8020/kylin/spark-historyIn web browser, access “http://sandbox:18080” it shows the job history:
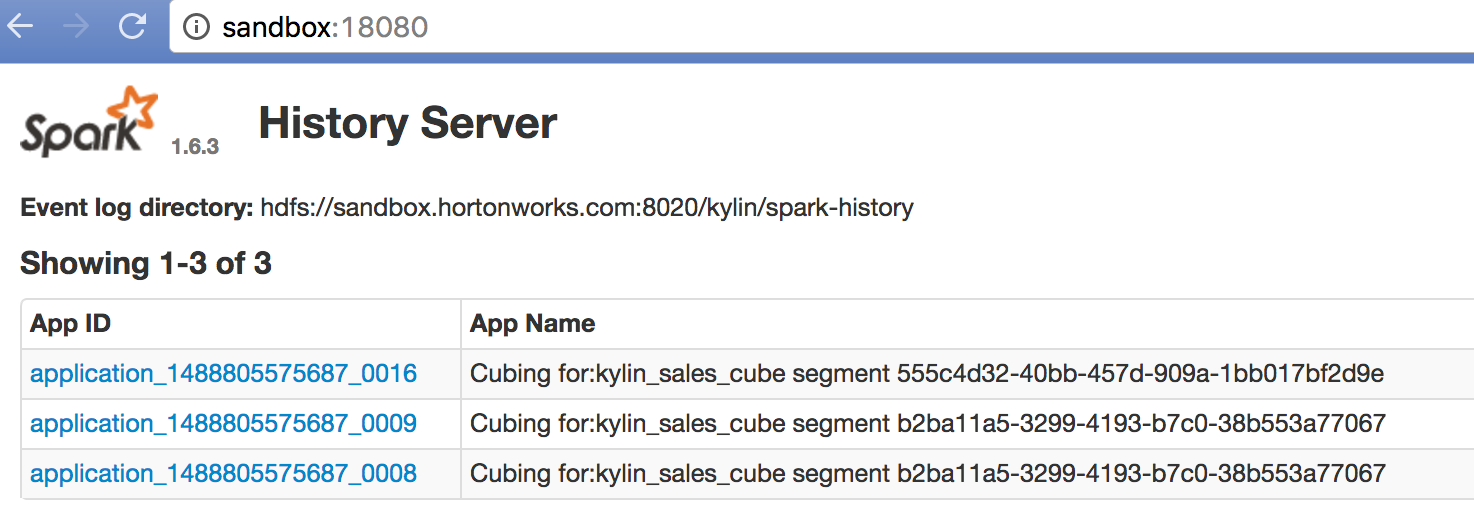
Click a specific job, there you will see the detail runtime information, that is very helpful for trouble shooting and performance tuning.
Go further
If you’re a Kylin administrator but new to Spark, suggest you go through Spark documents, and don’t forget to update the configurations accordingly. You can enable Spark Dynamic Resource Allocation so that it can auto scale/shrink for different work load. Spark’s performance relies on Cluster’s memory and CPU resource, while Kylin’s Cube build is a heavy task when having a complex data model and a huge dataset to build at one time. If your cluster resource couldn’t fulfill, errors like “OutOfMemorry” will be thrown in Spark executors, so please use it properly. For Cube which has UHC dimension, many combinations (e.g, a full cube with more than 12 dimensions), or memory hungry measures (Count Distinct, Top-N), suggest to use the MapReduce engine. If your Cube model is simple, all measures are SUM/MIN/MAX/COUNT, source data is small to medium scale, Spark engine would be a good choice. Besides, Streaming build isn’t supported in this engine so far (KYLIN-2484).
If you have any question, comment, or bug fix, welcome to discuss in dev@kylin.apache.org.