
Performance optimization of Kylin 4.0 in cloud -- local cache and soft affinity scheduling
01 Background Introduction
Recently, the Apache Kylin community released Kylin 4.0.0 with a new architecture. The architecture of Kylin 4.0 supports the separation of storage and computing, which enables kylin users to run Kylin 4.0 in a more flexible cloud deployment mode with flexible computing resources. With the cloud infrastructure, users can choose to use cheap and reliable object storage to store cube data, such as S3. However, in the architecture of separation of storage and computing, we need to consider that reading data from remote storage by computing nodes through the network is still a costly operation, which often leads to performance loss.
In order to improve the query performance of Kylin 4.0 when using cloud object storage as the storage, we try to introduce the local cache mechanism into the Kylin 4.0 query engine. When executing the query, the frequently used data is cached on the local disk to reduce the delay caused by pulling data from the remote object storage and achieve faster query response. In addition, in order to avoid wasting disk space when the same data is cached on a large number of spark executors at the same time, and the computing node can read more required data from the local cache, we introduce the scheduling strategy of soft affinity. The soft affinity strategy is to establish a corresponding relationship between the spark executor and the data file through some method, In most cases, the same data can always be read on the same executor, so as to improve the hit rate of the cache.
02 Implementation Principle
1. Local Cache
When Kylin 4.0 executes a query, it mainly goes through the following stages, in which the stages where local cache can be used to improve performance are marked with dotted lines:
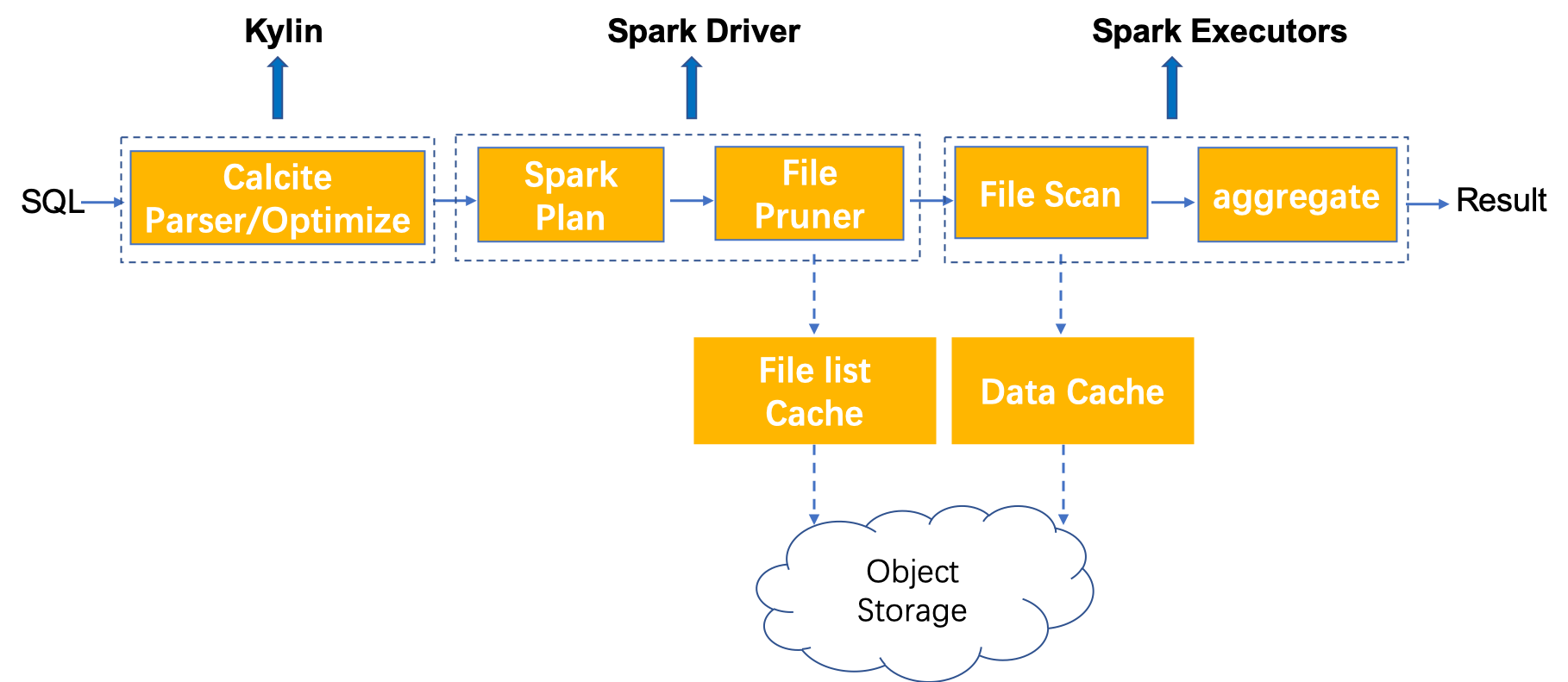
- File list cache:Cache the file status on the spark driver side. When executing the query, the spark driver needs to read the file list and obtain some file information for subsequent scheduling execution. Here, the file status information will be cached locally to avoid frequent reading of remote file directories.
- Data cache:Cache the data on the spark executor side. You can set the data cache to memory or disk. If it is set to cache to memory, you need to appropriately increase the executor memory to ensure that the executor has enough memory for data cache; If it is cached to disk, you need to set the data cache directory, preferably SSD disk directory.
Based on the above design, different types of caches are made on the driver side and the executor side of the query engine of kylin 4.0. The basic architecture is as follows:
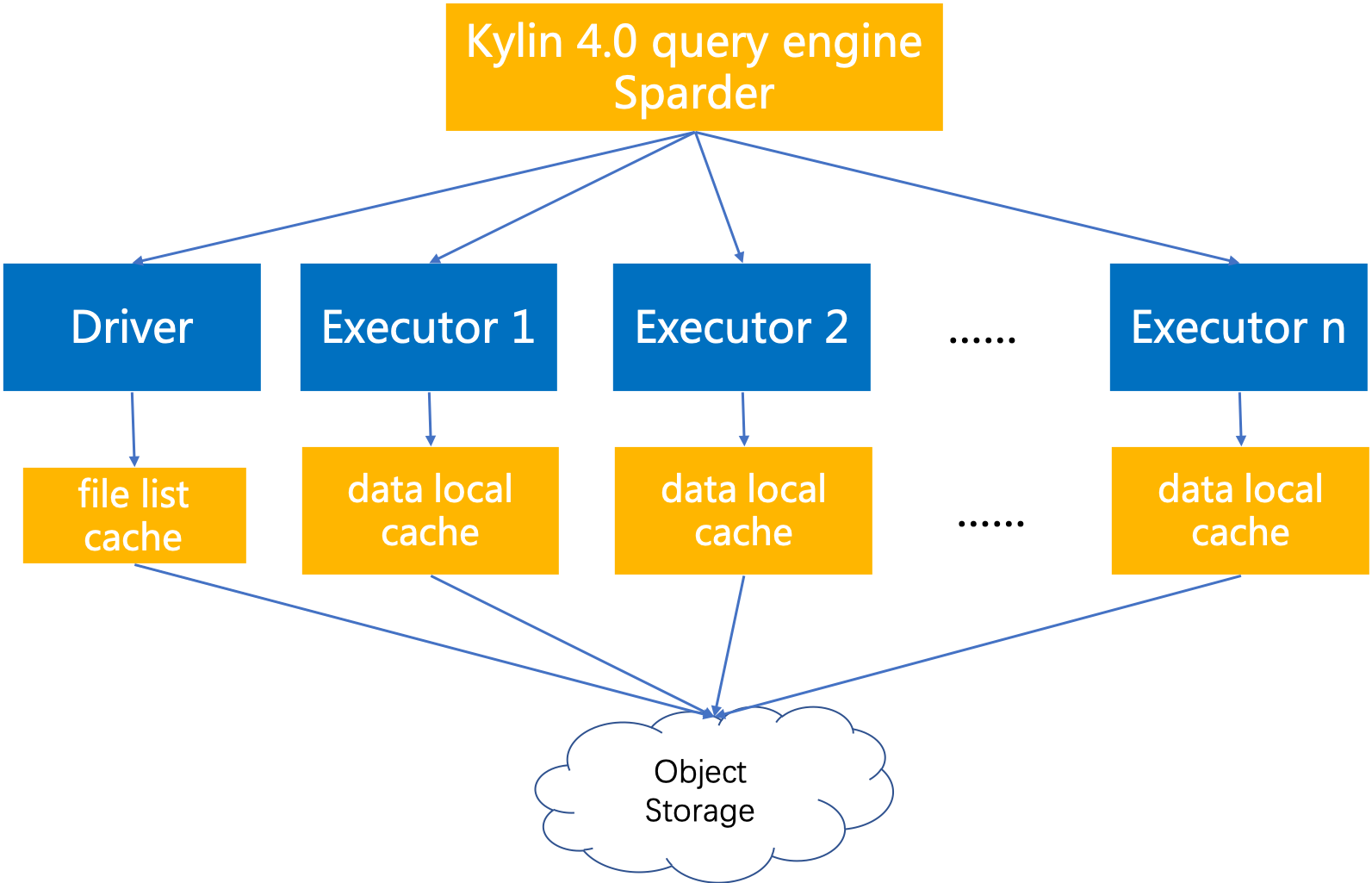
2. Soft Affinity Scheduling
When doing data cache on the executor side, if all data is cached on all executors, the size of cached data will be very considerable and a great waste of disk space, and it is easy to cause frequent evict cache data. In order to maximize the cache hit rate of the spark executor, the spark driver needs to schedule the tasks of the same file to the same executor as far as possible when the resource conditions are me, so as to ensure that the data of the same file can be cached on a specific one or several executors, and the data can be read through the cache when it is read again.
To this end, we calculate the target executor list by calculating the hash according to the file name and then modulo with the executor num. The number of executors to cache is determined by the number of data cache replications configured by the user. Generally, the larger the number of cache replications, the higher the probability of hitting the cache. When the target executors are unreachable or have no resources for scheduling, the scheduler will fall back to the random scheduling mechanism of spark. This scheduling method is called soft affinity scheduling strategy. Although it can not guarantee 100% hit to the cache, it can effectively improve the cache hit rate and avoid a large amount of disk space wasted by full cache on the premise of minimizing performance loss.
03 Related Configuration
According to the above principles, we implemented the basic function of local cache + soft affinity scheduling in Kylin 4.0, and tested the query performance based on SSB data set and TPCH data set respectively.
Several important configuration items are listed here for users to understand. The actual configuration will be given in the attachment at the end:
- Enable soft affinity scheduling:kylin.query.spark-conf.spark.kylin.soft-affinity.enabled
- Enable local cache:kylin.query.spark-conf.spark.hadoop.spark.kylin.local-cache.enabled
- The number of data cache replications, that is, how many executors cache the same data file:kylin.query.spark-conf.spark.kylin.soft-affinity.replications.num
- Cache to memory or local directory. Set cache to memory as buff and cache to local as local: kylin.query.spark-conf.spark.hadoop.alluxio.user.client.cache.store.type
- Maximum cache capacity:kylin.query.spark-conf.spark.hadoop.alluxio.user.client.cache.size
04 Performance Benchmark
We conducted performance tests in three scenarios under AWS EMR environment. When scale factor = 10, we conducted single concurrent query test on SSB dataset, single concurrent query test and 4 concurrent query test on TPCH dataset. S3 was configured as storage in the experimental group and the control group. Local cache and soft affinity scheduling were enabled in the experimental group, but not in the control group. In addition, we also compare the results of the experimental group with the results when HDFS is used as storage in the same environment, so that users can intuitively feel the optimization effect of local cache + soft affinity scheduling on deploying Kylin 4.0 on the cloud and using object storage as storage.
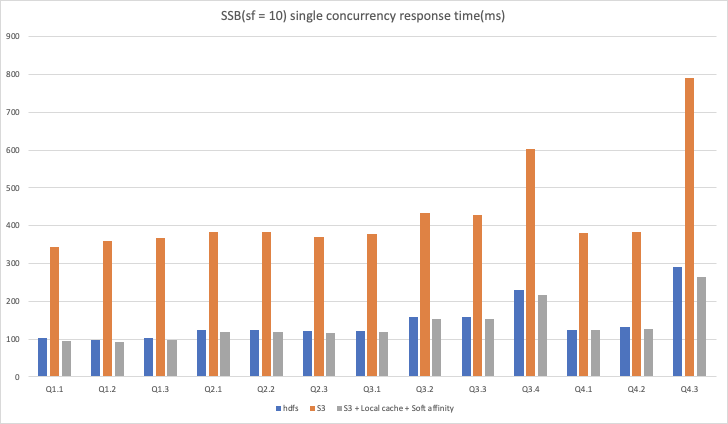
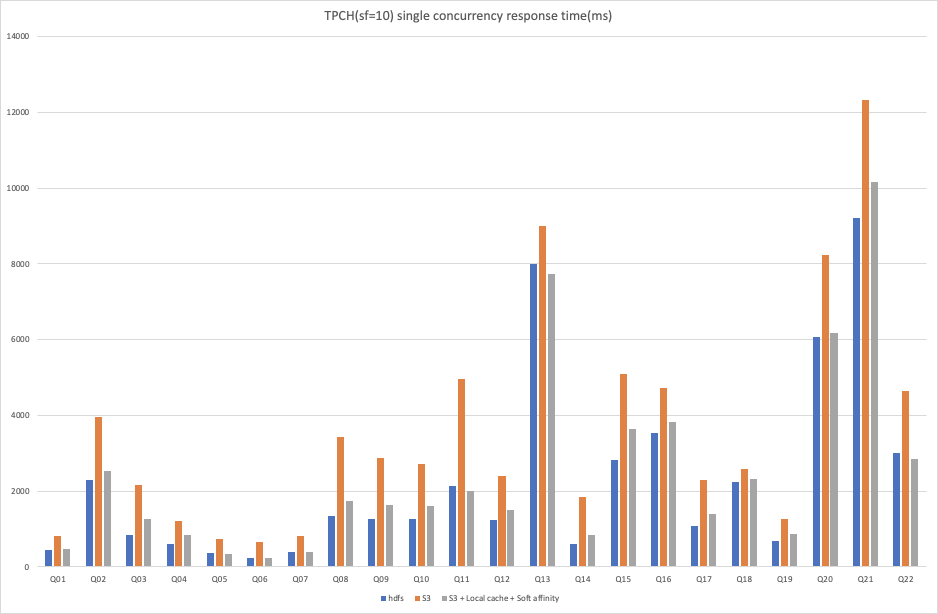
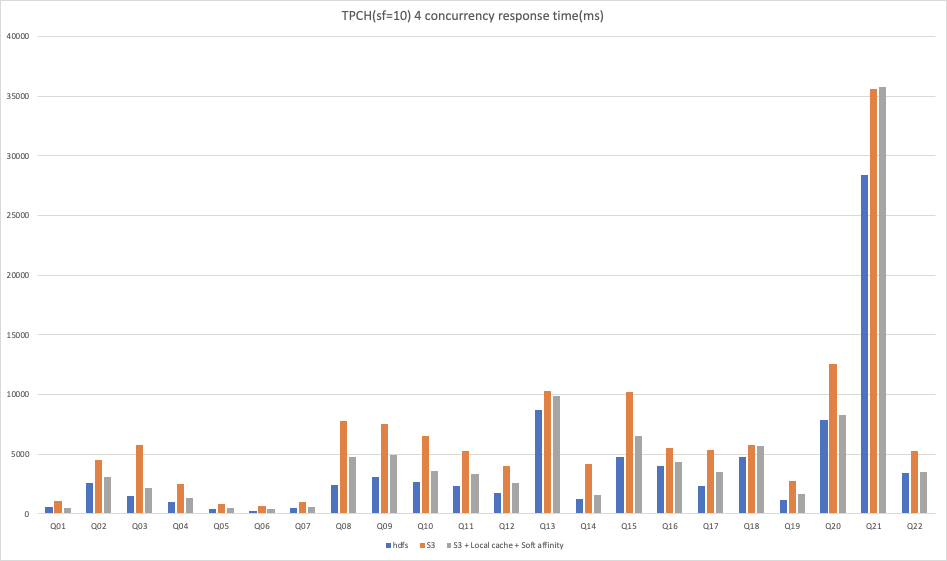
As can be seen from the above results:
- In the single concurrency scenario of SSB data set, when S3 is used as storage, turning on the local cache and soft affinity scheduling can achieve about three times the performance improvement, which can be the same as that of HDFS, or even improved.
- Under TPCH data set, when S3 is used as storage, whether single concurrent query or multiple concurrent query, after local cache and soft affinity scheduling are enabled, the performance of all queries can be greatly improved.
However, in the comparison results of Q21 under the 4 concurrent tests of TPCH dataset, we observed that the results of enabling local cache and soft affinity scheduling are lower than those when using S3 alone as storage. Here, it may be that the data is not read through the cache for some reason. The underlying reason is not further analyzed in this test, in the subsequent optimization process, we will gradually improve. Moreover, because the query of TPCH is complex and the SQL types are different, compared with the results of HDFS, the performance of some SQL is improved, while the performance of some SQL is slightly insufficient, but generally speaking, it is very close to the results of HDFS as storage.
The result of this performance test is a preliminary verification of the performance improvement effect of local cache + soft affinity scheduling. On the whole, local cache + soft affinity scheduling can achieve significant performance improvement for both simple queries and complex queries, but there is a certain performance loss in the scenario of high concurrent queries.
If users use cloud object storage as Kylin 4.0 storage, they can get a good performance experience when local cache + soft affinity scheduling is enabled, which provides performance guarantee for Kylin 4.0 to use the separation architecture of computing and storage in the cloud.
05 Code Implementation
Since the current code implementation is still in the basic stage, there are still many details to be improved, such as implementing consistent hash, how to deal with the existing cache when the number of executors changes, so the author has not submitted PR to the community code base. Developers who want to preview in advance can view the source code through the following link:
The code implementation of local cache and soft affinity scheduling
06 Related Link
You can view the performance test result data and specific configuration through the link:
The benchmark of Kylin4.0 with local cache and soft affinity scheduling