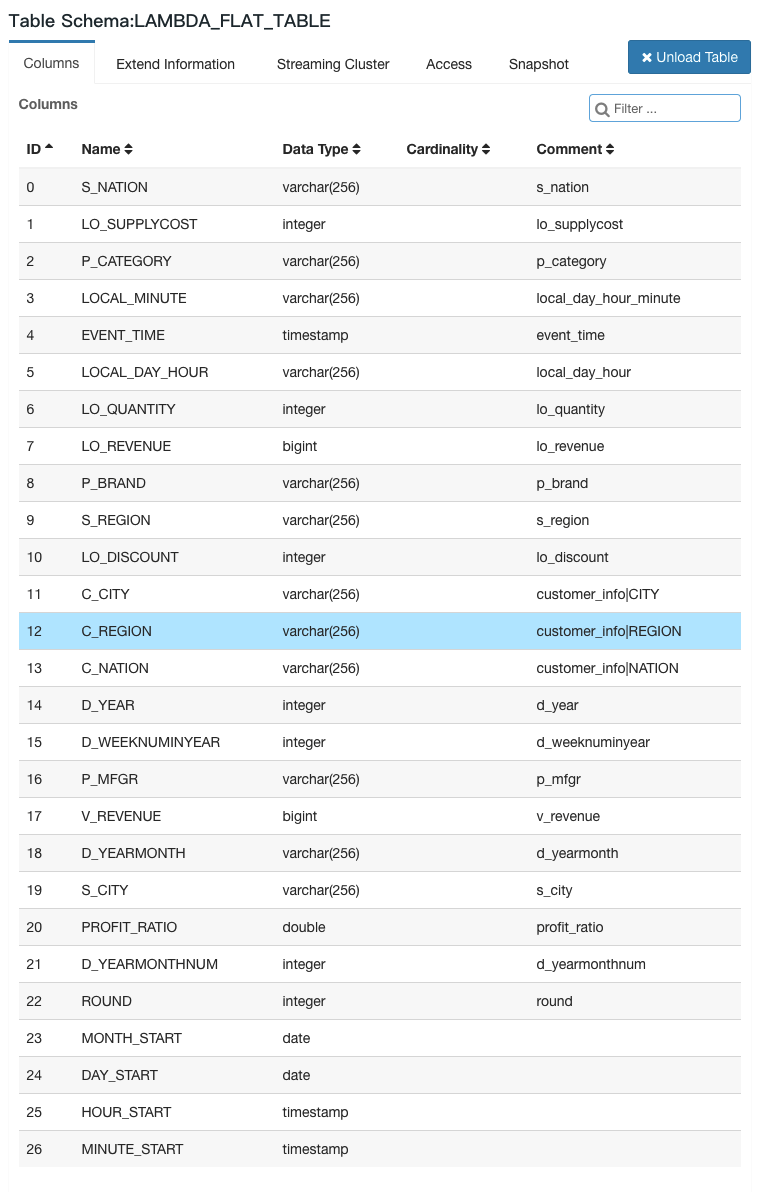
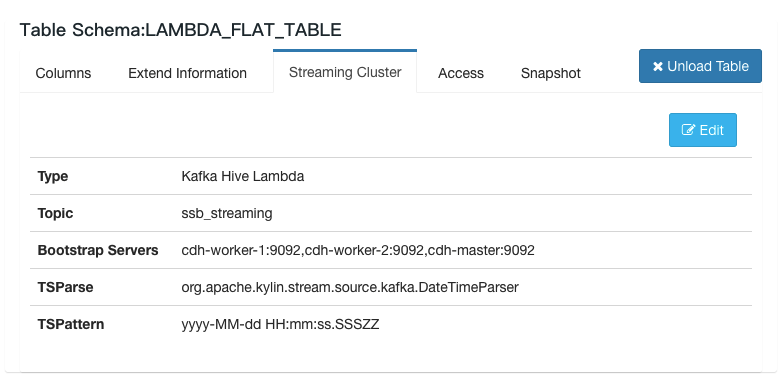
Kylin v3.0.0 will release the real-time OLAP feature, by the power of newly added streaming reciever cluster, Kylin can query streaming data with sub-second latency. You can check this tech blog for the overall design and core concept.
If you want to find a step by step tutorial, please check this this tech blog.
In this article, we will introduce how to update segment and set timezone for derived time column in realtime OLAP cube.
Background
Says we have Kafka message which looks like this:
{
"s_nation":"SAUDI ARABIA",
"lo_supplycost":74292,
"p_category":"MFGR#0910",
"local_day_hour_minute":"09_21_44",
"event_time":"2019-12-09 08:44:50.000-0500",
"local_day_hour":"09_21",
"lo_quantity":12,
"lo_revenue":1411548,
"p_brand":"MFGR#0910051",
"s_region":"MIDDLE EAST",
"lo_discount":5,
"customer_info":{
"CITY":"CHINA 057",
"REGION":"ASIA",
"street":"CHINA 05721",
"NATION":"CHINA"
},
"d_year":1994,
"d_weeknuminyear":30,
"p_mfgr":"MFGR#09",
"v_revenue":7429200,
"d_yearmonth":"Jul1994",
"s_city":"SAUDI ARA15",
"profit_ratio":0.05263157894736842,
"d_yearmonthnum":199407,
"round":1
}This sample comes from SSB with some additional fields such as event_time. We have the field such as event_time, which stands for the timestamp of current event.
And we assume that event come from countries of different timezone, “2019-12-09 08:44:50.000-0500” indicated that event applies America/New_York timezone. You may have some events which come from Asia/Shanghai as well.
local_day_hour_minute is a column which value is in local timezone, eg. “GMT+8” in the above sample.
Question
When perform realtime OLAP analysis with Kylin, you may have some concerns included:
- Will events in different timezones cause incorrect query results?
- How could I make it correct when kafka messages contain the value which is not what you want, says some dimension value is misspelled?
- How could I retrieve long-late messages which has been dropped?
- My query only hit a small range of time, how should I write filter condition to make sure unused segments are purged/skipped from scan?
Quick Answer
For the first question, you can always get the correct result in the right timezone of location by set kylin.stream.event.timezone=GMT+N for all Kylin processes. By default, UTC is used for derived time column.
For the second and third question, in fact you cannot update/append segment to a normal streaming cube, but you can update/append a streaming cube which in lambda mode, all you need to prepare is creating a Hive table which is mapped to your kafka event.
For the fourth question, you can achieved this by adding derived time column in your filter condition like MINUTE_START/DAY_START etc.
How to do
Configure timezone
We know message may come from different timezone, but you want query results using some specific timezone.
For example, if you live in some place in GMT+2, please set kylin.stream.event.timezone=GMT+2 for all Kylin process.
Create lambda table
You should create a hive table in default namespace, and this table should contains all your dimension and measure columns, please
remember to include derived time column like MINUTE_START/DAY_START if you set them in your cube’s dimension column.
Depend on which granularity level you want to update segment, you can choose HOUR_START* or DAY_START as partition column of this hive table.
use default;
CREATE EXTERNAL TABLE IF NOT EXISTS lambda_flat_table
(
-- event timestamp and debug purpose column
EVENT_TIME timestamp
,ROUND bigint COMMENT "For debug purpose, in which round did this event sent by producer"
,LOCAL_DAY_HOUR string COMMENT "For debug purpose, maybe check timezone etc"
,LOCAL_MINUTE string COMMENT "For debug purpose, maybe check timezone etc"
-- dimension column on fact table
,LO_QUANTITY bigint
,LO_DISCOUNT bigint
-- dimension column on dimension table
,C_REGION string
,C_NATION string
,C_CITY string
,D_YEAR int
,D_YEARMONTH string
,D_WEEKNUMINYEAR int
,D_YEARMONTHNUM int
,S_REGION string
,S_NATION string
,S_CITY string
,P_CATEGORY string
,P_BRAND string
,P_MFGR string
-- measure column on fact table
,V_REVENUE bigint
,LO_SUPPLYCOST bigint
,LO_REVENUE bigint
,PROFIT_RATIO double
-- for kylin used
,MINUTE_START timestamp
,HOUR_START timestamp
,MONTH_START date
)
PARTITIONED BY (DAY_START date)
STORED AS SEQUENCEFILE
LOCATION 'hdfs:///LacusDir/lambda_flat_table';Create streaming cube in Kylin
The first step is to add information like broker list and topic name;
after that, you should paste sample message into left and let Kylin auto-detect the column name and column type.
You may find some data type is not correct, please fix them manually and make sure they are aligned to the data type in Hive table.
For example, you should change the data type of event_time from varchar to timestamp.
And some column names are not the same as Hive Table, so please correct them too, such as customer_info_REGION to C_REGION.
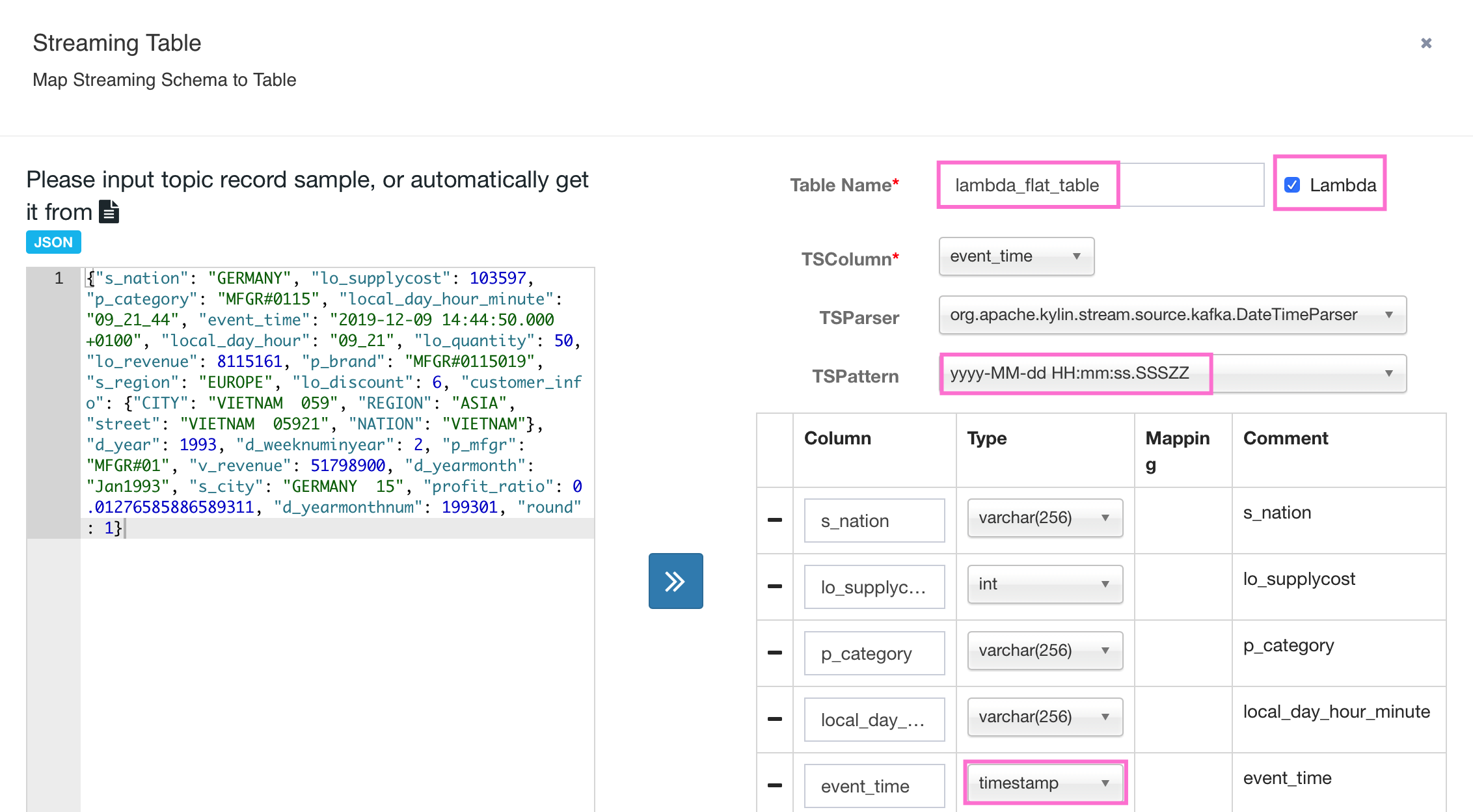
After that, please choose the right TSColumn TSParser and correct Table Name, table name should be identical to the name of Hive Table. After that, you should click submit buttom.
If you are lucky enough, table meta info will be saved successfully, otherwise please correct data type and column name according to output message.
When you are creating Model, please set Partition Date Column with the right value. For streaming cube, Partition Date Column is used to generate HQL in updating segment which source data is from Hive.
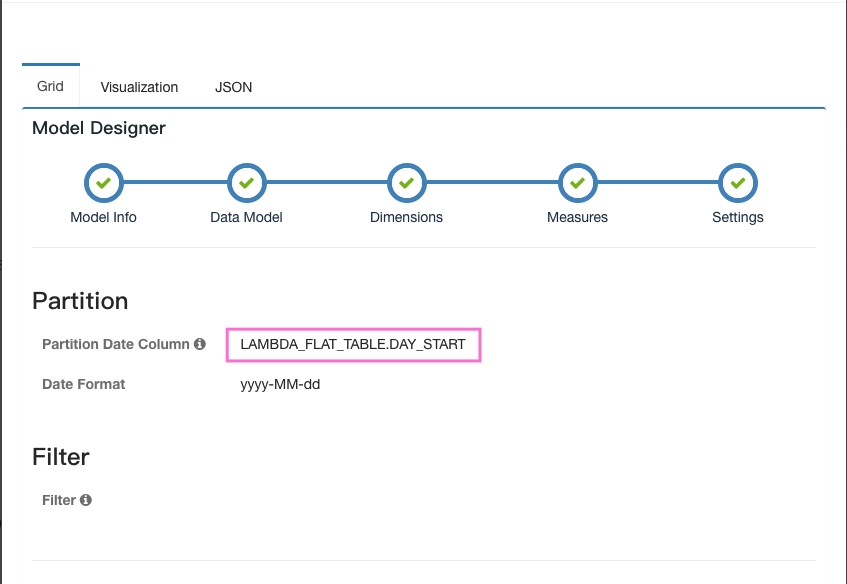
Check result with timezone
Let us do a quick check to compare whether LOCAL_MINUTE is aligned to HOUR_START.
SELECT LOCAL_MINUTE, HOUR_START, sum(LO_SUPPLYCOST)
FROM LAMBDA_FLAT_TABLE
WHERE day_start = '2019-12-09'
GROUP BY LOCAL_MINUTE, HOUR_START
ORDER BY LOCAL_MINUTE, HOUR_START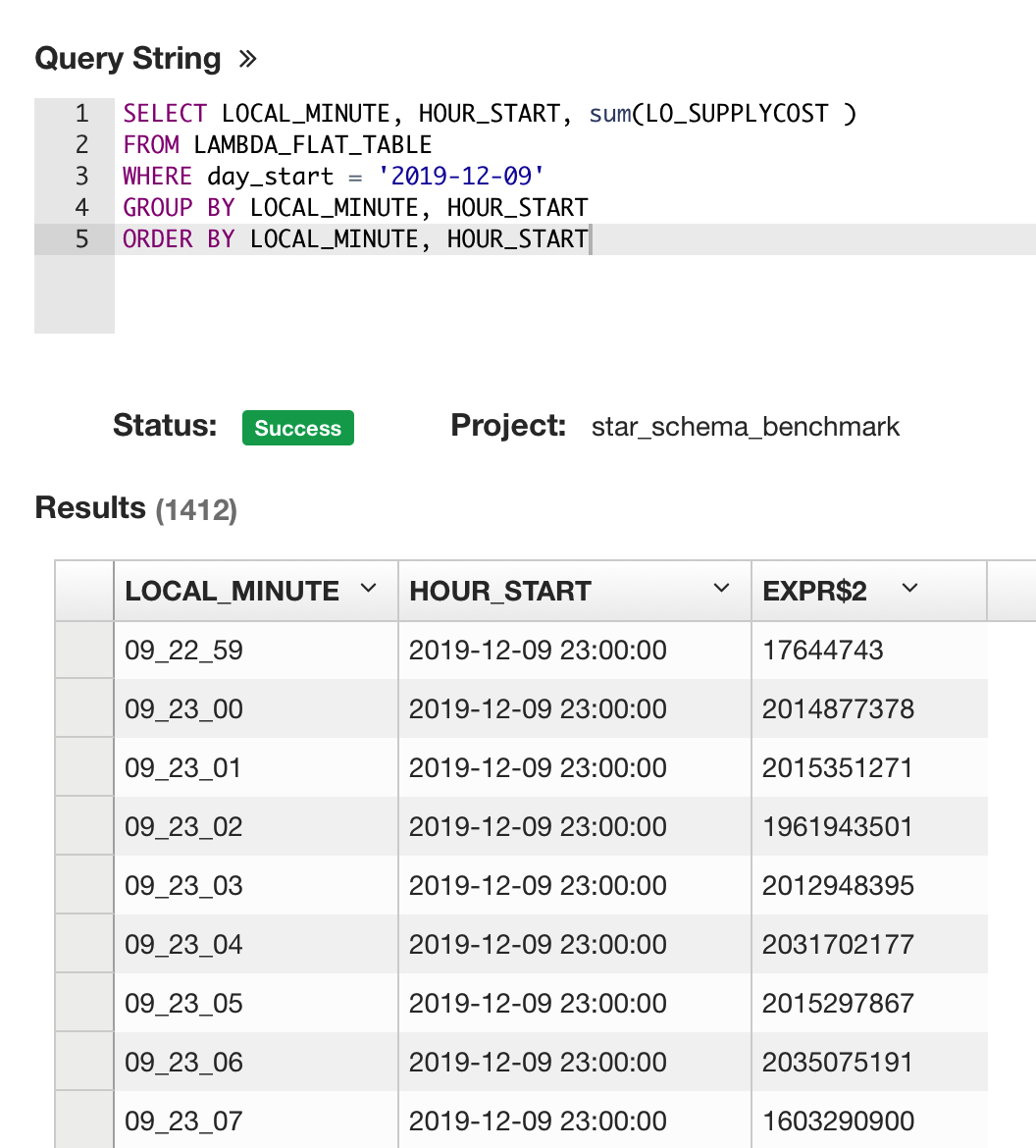
Update segment
- Use some ETL tools like spark streaming to write correct data into HDFS, and add new partition based on your new data files.
- After that, use Rest API
http://localhost:7070/kylin/api/cubes/{cube_name}/rebuild[Put Method] to submit a build job to replace old segments,
please add offset according to timezone instartTimeandendTimeif you have setkylin.stream.event.timezone. - In some case, you want to add to a lot of historical data into Kylin streaming cube to analyse(not replace something), you can also use the method.
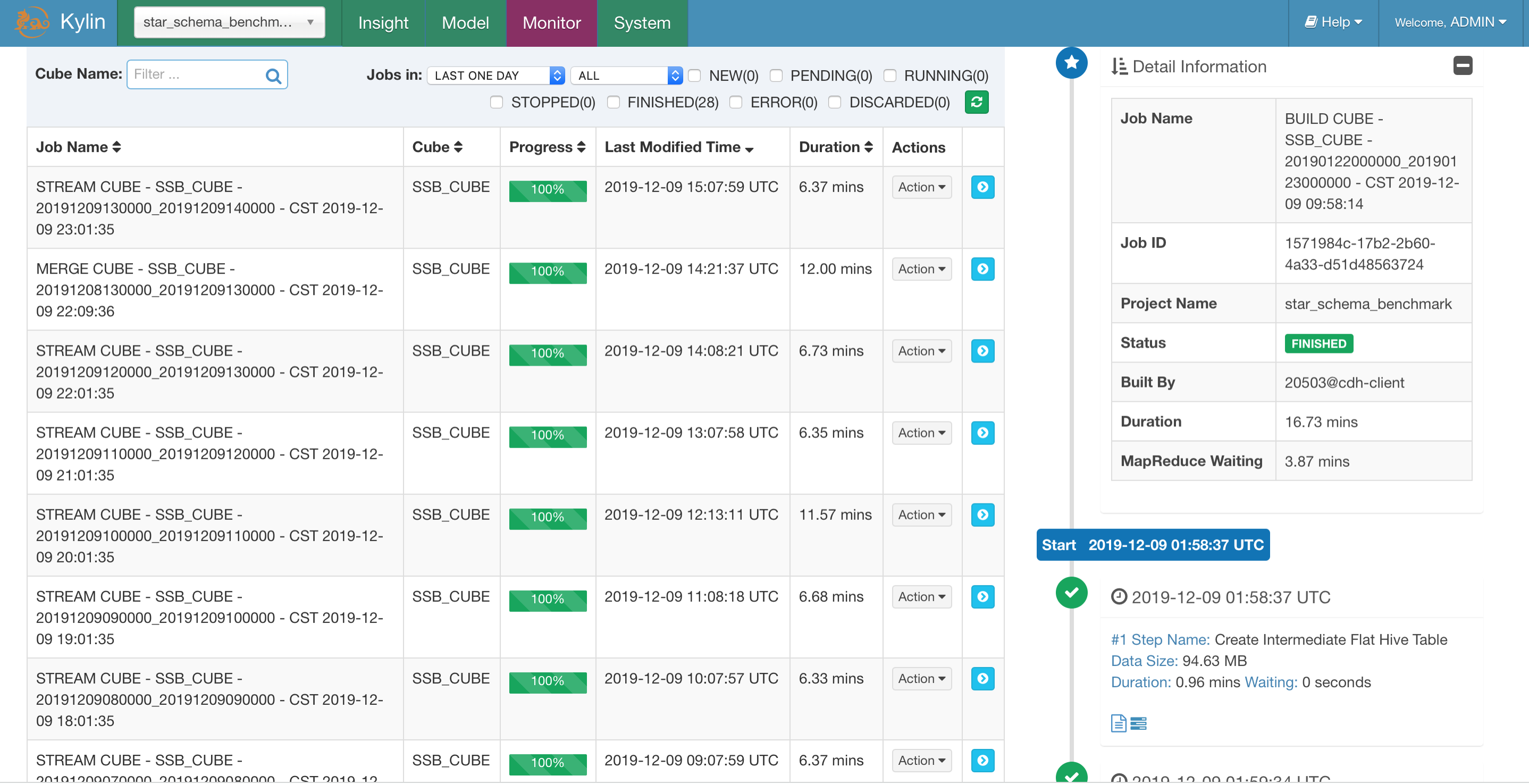
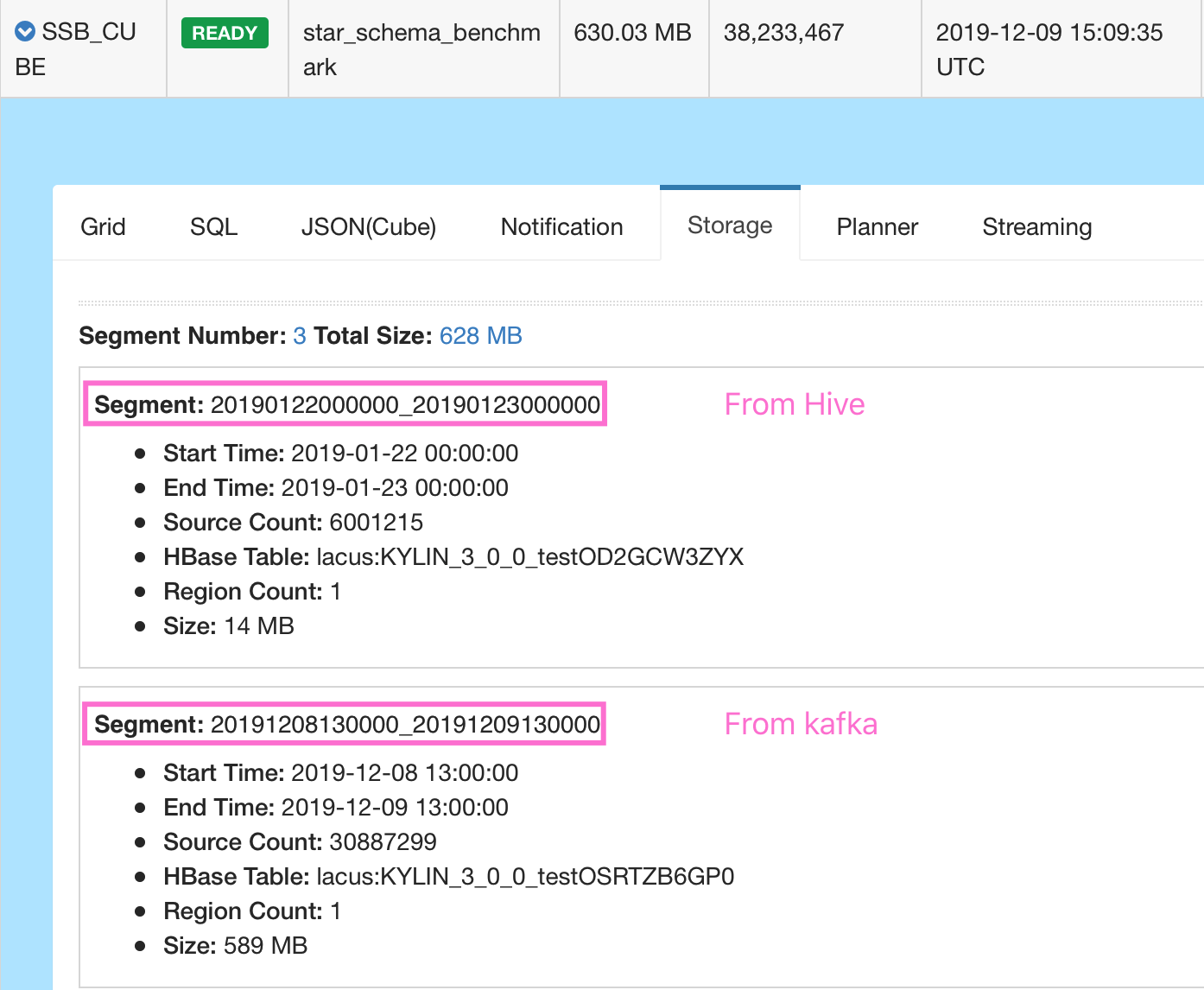
Some screenshots