
Kylin on Cloud —— 两小时快速搭建云上数据分析平台(下)
以下部分为 Kylin on Cloud —— 两小时快速搭建云上数据分析平台 的下篇,上篇请查看:Kylin on Cloud —— 两小时快速搭建云上数据分析平台(上)
Kylin 查询集群
启动 Kylin 查询集群
1.在启动构建集群时使用的 kylin_configs.yaml 的基础上,打开 mdx 开关:
ENABLE_MDX: &ENABLE_MDX 'true'
2.然后执行部署命令启动集群:
python deploy.py --type deploy --mode query
体验 kylin 的查询速度
1.查询集群启动成功后,先执行 python deploy.py --type list 命令来列出所有节点信息,然后在浏览器输入 http://${kylin_node_public_ip}:7070/kylin 检查 kylin UI:
2.在 Insight 页面执行与之前在 spark-sql 中相同的 sql:
select TAXI_TRIP_RECORDS_VIEW.PICKUP_DATE, NEWYORK_ZONE.BOROUGH, count(*), sum(TAXI_TRIP_RECORDS_VIEW.TRIP_TIME_HOUR), sum(TAXI_TRIP_RECORDS_VIEW.TOTAL_AMOUNT)
from TAXI_TRIP_RECORDS_VIEW
left join NEWYORK_ZONE
on TAXI_TRIP_RECORDS_VIEW.PULOCATIONID = NEWYORK_ZONE.LOCATIONID
group by TAXI_TRIP_RECORDS_VIEW.PICKUP_DATE, NEWYORK_ZONE.BOROUGH;
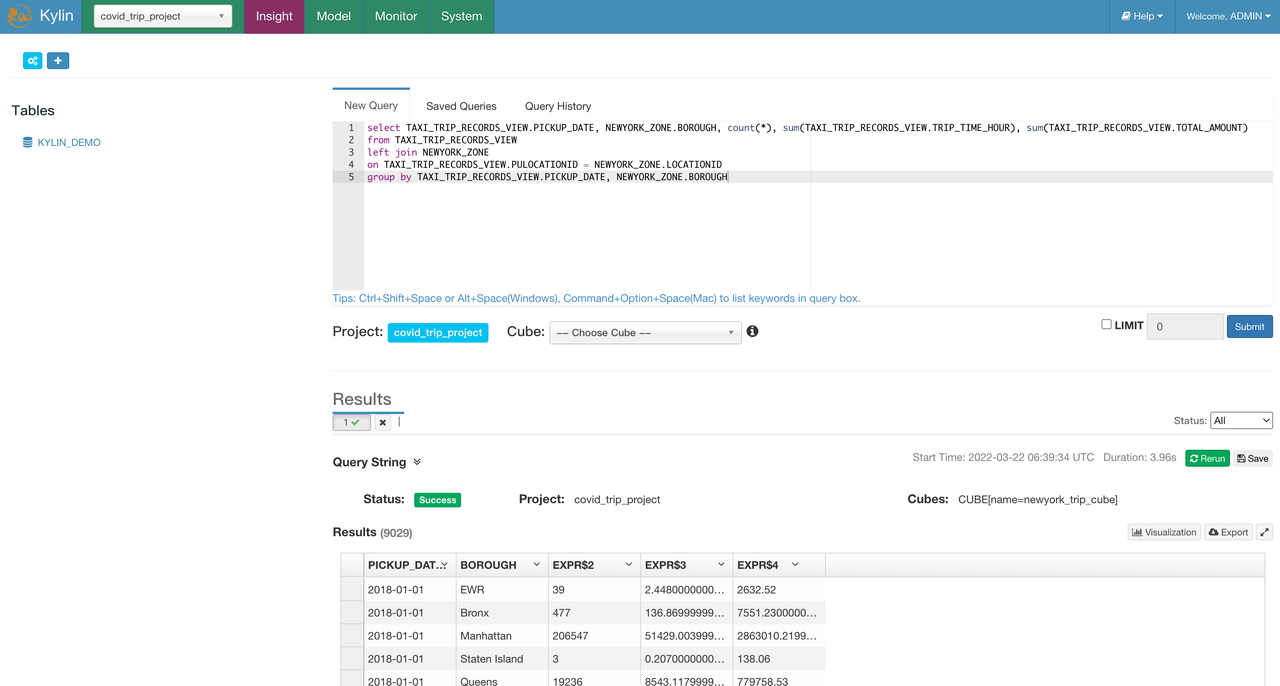
可以看到,在查询击中 cube 的情况下,也就是查询结果直接来自于预计算后的数据,只使用了大概 4 秒的时间就返回了查询结果,大大节省了查询时间。
预计算降低查询成本
在对比原生 SparkSql 和 Kylin 查询速度的测试中,我们使用的数据集是纽约市出租车订单数据,事实表共有 2 亿+ 数据。从对比结果可以看到,在上亿的大数据分析场景下,Kylin 能够显著提升查询效率,通过一次构建加速上千上万次业务查询,极大的降低查询成本。
配置语义层
向 MDX for Kylin 导入 Dataset
在 MDX for Kylin 中可以根据所连接的 Kylin 中的 Cube 来创建 Dataset,定义 Cube 关系,创建业务指标。为方便体验,用户可以直接从 S3 下载 Dataset 文件导入到 MDX for Kylin 中:
1.从 S3 下载 Dataset 文件到本地机器
wget https://s3.cn-north-1.amazonaws.com.cn/public.kyligence.io/kylin/kylin_demo/covid_trip_project_covid_trip_dataset.json
2.访问 MDX for Kylin 界面
在浏览器输入 http://${kylin_node_public_ip}:7080 访问 MDX for Kylin 页面,以 ADMIN/KYLIN 的用户名密码组合登录:
3.确认 Kylin 连接
MDX for Kylin 中已经配置了需要连接的 kylin 节点的信息,首次登录需要输入 kylin 节点的用户名和密码也就是 ADMIN/KYLIN:

4.导入 Dataset
连接 Kylin 成功后点击右上角的图标退出管理界面:
切换到 covid_trip_project 项目,在 Dataset 页面中点击 Import Dataset:
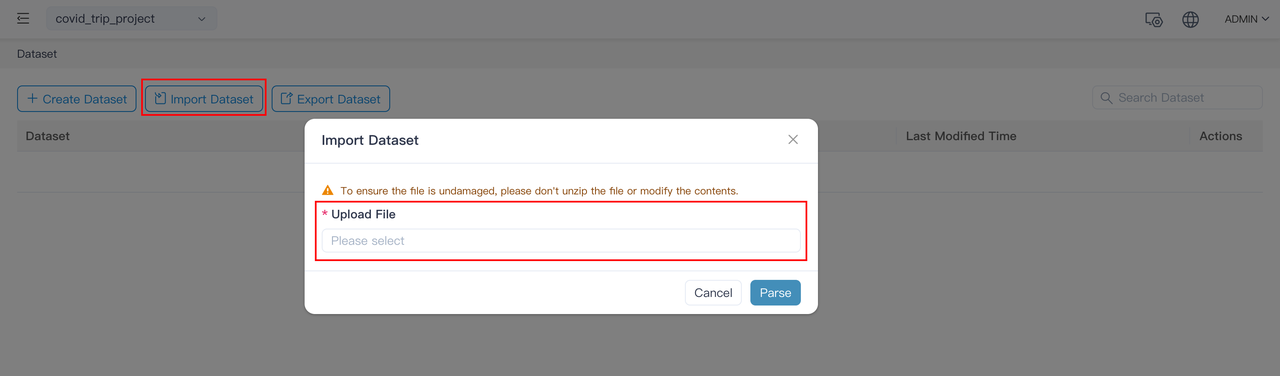
选择刚刚从 S3 下载的文件 covid_trip_project_covid_trip_dataset.json 导入。
covid_trip_dataset 中定义了各原子指标的年累计、月累计、年增速、月增速,和时间层级、地区层级等特殊维度、度量,以及新冠肺炎病死率、出租车平均速度等业务指标。如何手动创建 Dataset 请参考:Create dataset in MDX for Kylin,MDX for Kylin 手册链接请参考:MDX for Kylin 使用手册。
数据分析
通过 Tableau 进行数据分析
我们以本地 windows 机器上的 tableau 为例连接 MDX for Kylin 进行数据分析。
1.选择 Tableau 内置的 Microsoft Analysis Service 来连接 MDX for Kylin (需要提前安装 Microsoft Analysis Services 驱动,可从 tableau 官网下载,Microsoft Analysis Services 驱动下载)
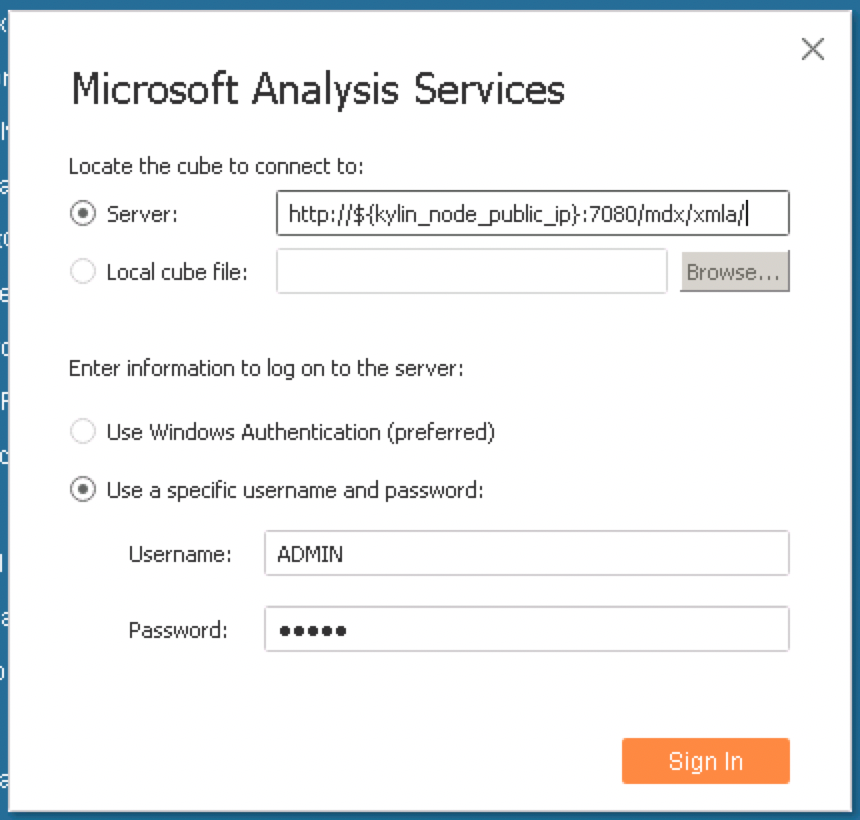
2.在弹出的设置页面中填写 MDX for Kylin 的连接地址,以及用户名和密码,连接地址为 http://${kylin_node_public_ip}:7080/mdx/xmla/covid_trip_project:
3.选择 covid_trip_dataset 作为数据集:
4.然后即可在工作表中进行数据分析,由于我们在 MDX for Kylin 中已经统一定义了业务指标,所以在 tableau 中制作数据分析报表时,可以直接拖拽定义好的业务指标到工作表中进行展示。
5.首先分析疫情数据,通过确诊人数、病死率两个指标来绘制国家级别的疫情地图,只需要将地区层级中的 COUNTRY_SHORT_NAME 放到工作表的列中 ,将事先定义好的新增确诊人数总和 SUM_NEW_POSITIVE_CASES 和病死率指标 CFR_COVID19 放到工作表的行中,然后选择以地图形式展示数据结果:
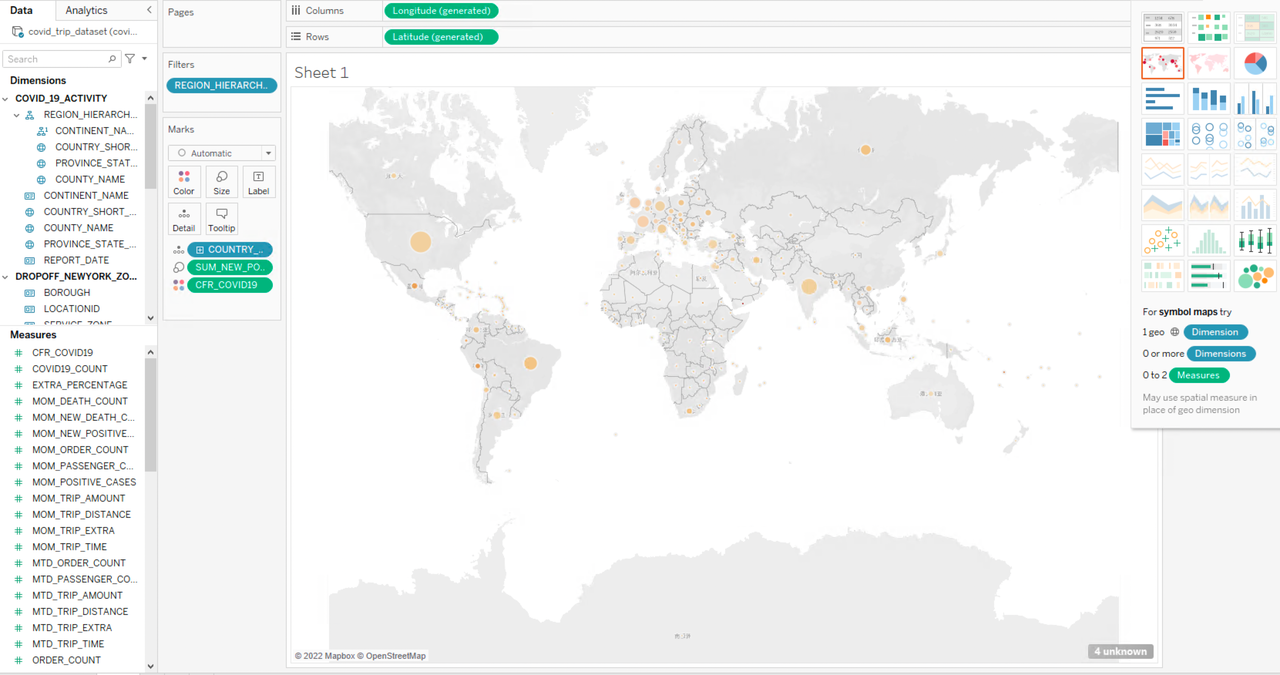
其中,图标面积代表死亡人数级别,图标颜色深浅代表病死率级别。通过疫情地图可以看出,美国和印度的确诊人数相对较多,但是这两个国家的病死率与其他大多数国家没有明显差别;而确诊人数很少的秘鲁、瓦努阿图、墨西哥等国家的病死率则居高不下。从这个现象入手,也许可以挖掘到更深层次的原因。
由于我们设置了地区层级,所以可以将国家级别的疫情地图下钻到省级别,查看各个国家内部各个地区的疫情情况:
在 province 级别的疫情地图放大看美国的疫情状况:
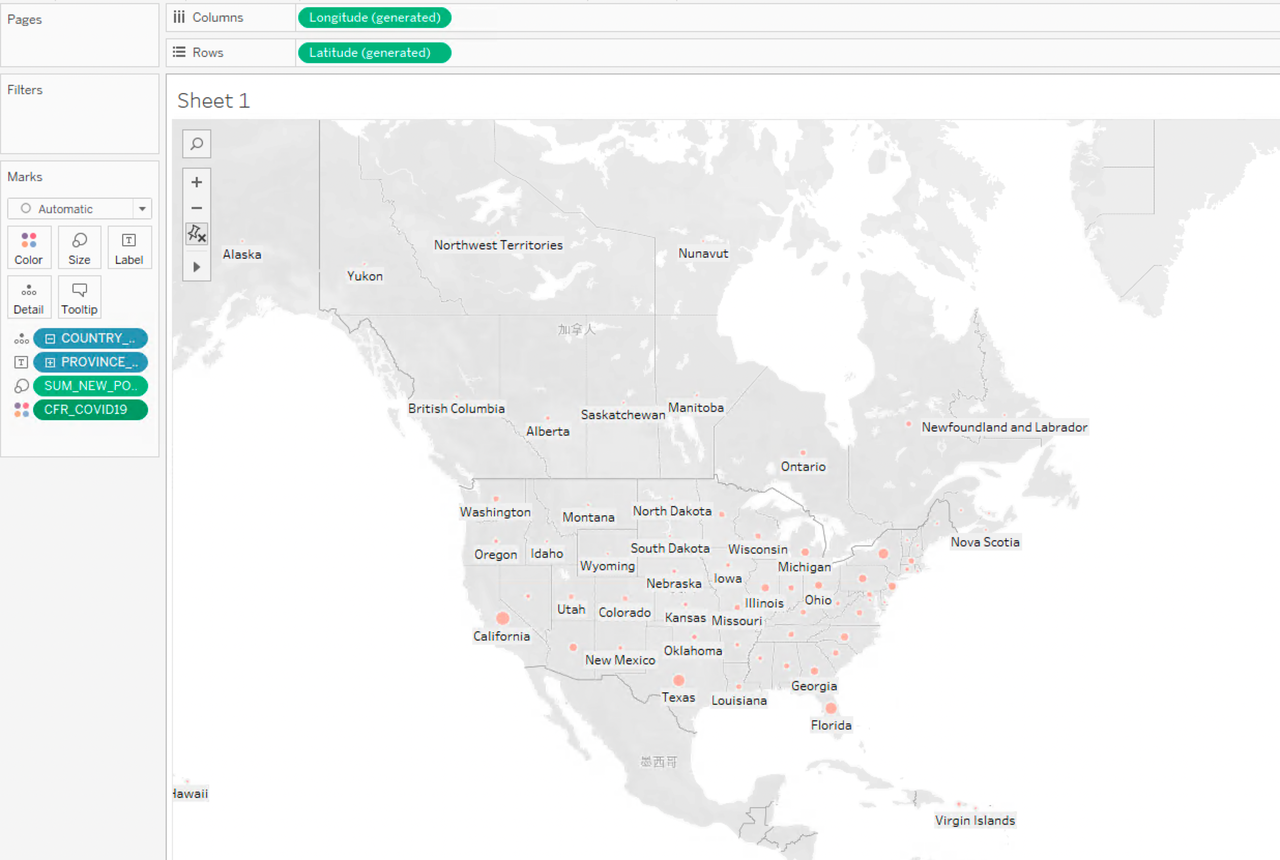
可以发现,美国每个州的病死率没有明显差距,都在 0.01 左右;在确诊人数上,California、Texas、Florida 以及纽约市几个地区明显偏高,这几个地区经济发达、人口众多,新冠肺炎确诊人数也随之攀升。下面针对纽约市出租车数据集,结合疫情发展情况,分析疫情形势下人们乘坐出租车出行的数据变化。
6.对于纽约市出租车订单数据集,分别从以下两个业务问题入手:
- 分析纽约市各个街区出行特征,对比订单数量、出行速度等出行指标
将 lookup 表 PICKUP_NEWYORK_ZONE 中的字段 BOROUGH 拖拽到工作表的列中,将指标 ORDER_COUNT、trip_mean_speed 拖拽到工作表的行中,以符号地图的方式展示,颜色深浅代表平均速度、面积大小代表订单数量,可以看到从曼哈顿区出发的出租车订单比别的街区总和都要高,但是平均速度最小,Queens 街区次之,Staten Island 则是出租车活动最少的一个街区。从 Bronx 出发的出租车平均速度高达 82 英里/小时,比其他街区的平均速度都高出几倍。从这些出行特征可以映射出纽约市各个街区的人口密集程度以及经济发达程度。
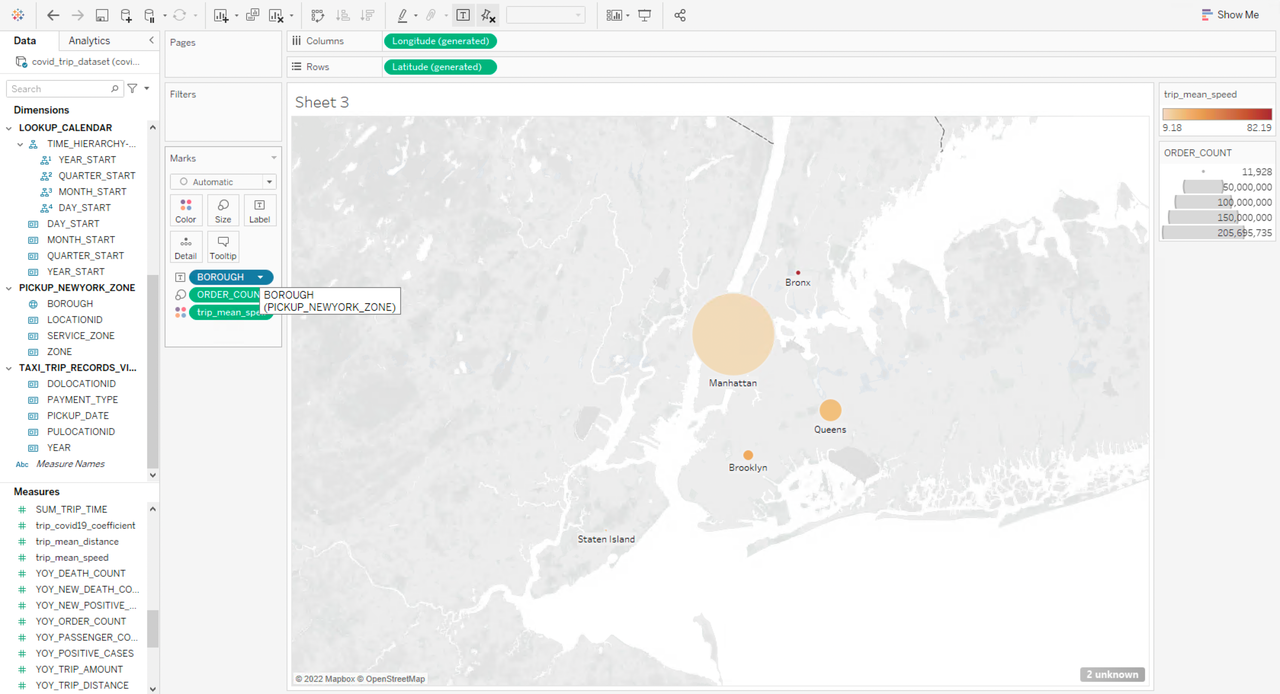
然后将 lookup 表 PICKUP_NEWYORK_ZONE 中的字段 BOROUGH 换成 DROPOFF_NEWYORK_ZONE 中的 BOROUGH,统计出租车订单到达街区的数量和平均速度:
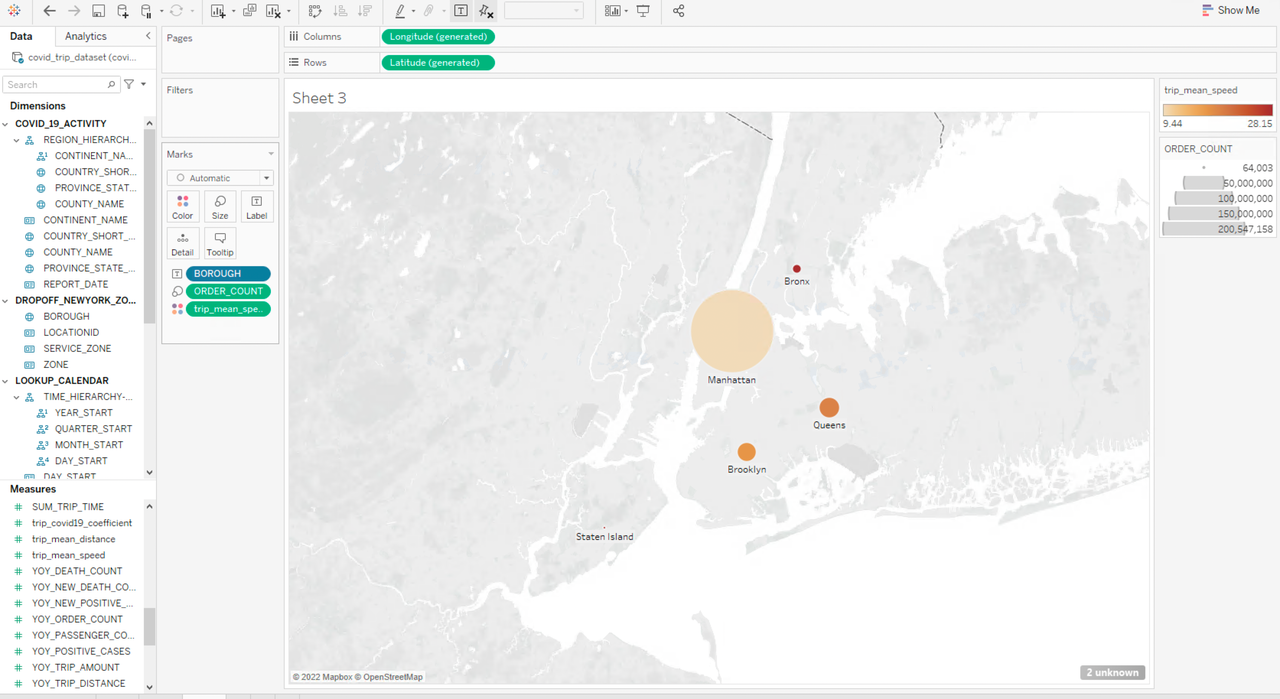
相比出发街区的数据,brookly、Queens 和 Bronx 三个街区的到达数据都有比较明显的差别,从比例关系上来看,到达 brookly 和 Bronx 的出租车订单要远远多于从 Brookly 和 Bronx 出发的订单,到达 Queens 街区的订单数量则明显小于从 Queens 街区出发的订单。
- 疫情前后纽约市居民乘坐出租车的出行习惯变化,更偏向远程出行还是近程
通过平均出行里程分析居民出行习惯变化,将维度 MONTH_START 拖拽到工作表的行,将指标 trip_mean_distance 拖拽到工作表的列:
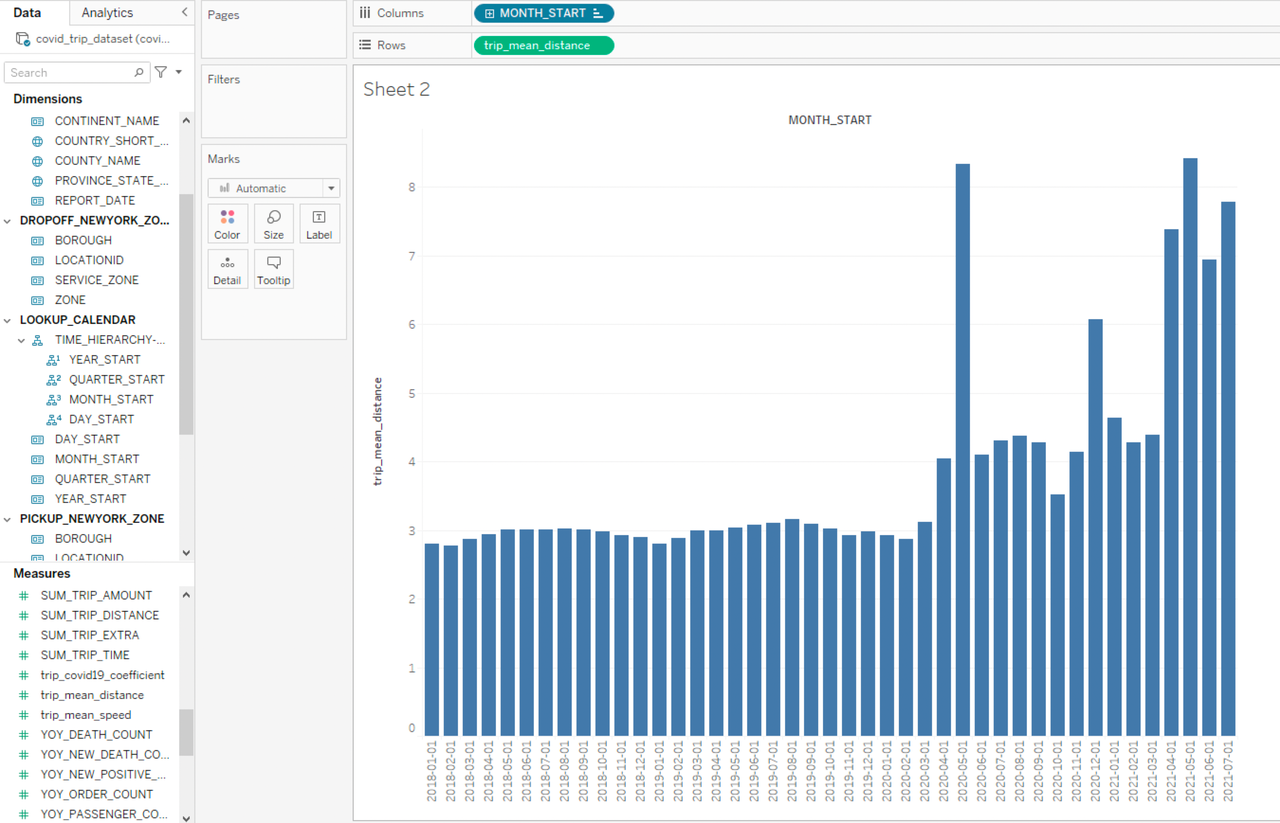
根据柱状图的结果可以发现,疫情前后人们的出行习惯发生了明显的变化,从 2020.03 开始平均出行里程有明显升高,甚至有的月份发生数倍增长,并且疫情开始后每个月的平均出行里程变的很不稳定。基于这种数据表现,我们可以再结合月份维度的疫情数据进行联合分析,将 SUM_NEW_POSITIVE_CASES 和 MTD_ORDER_COUNT 拖拽到工作表的行中,并在筛选器中增加筛选条件 PROVINCE_STATE_NAME=New York:
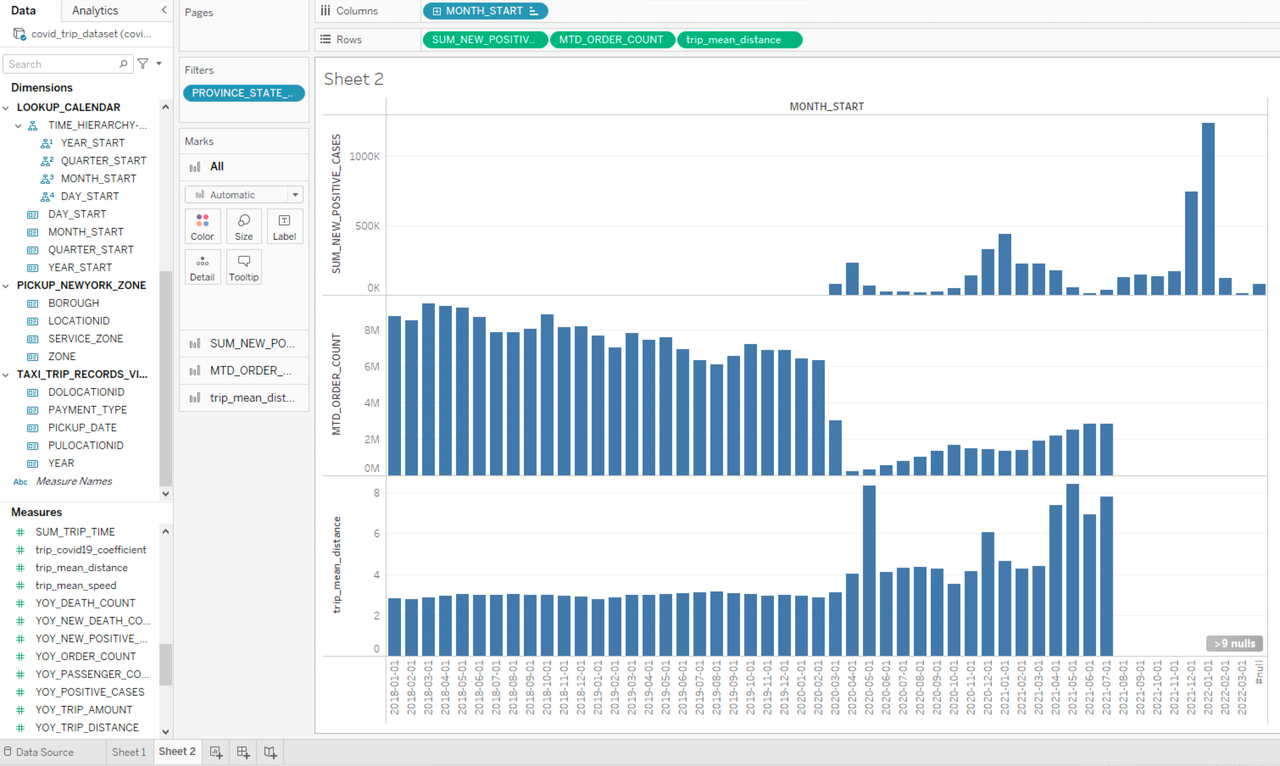
可以看到一个有趣的现象,疫情初期刚刚爆发的时候出租车订单量急剧减少,而平均出行里程增大,说明大家减少了很多不必要的短距离出行,或者采用出租车以外的更安全的交通方式进行了短距离出行。对比三种数据的曲线变化,可以看到疫情严重程度和人们的出行情况表现出很高的相关性,疫情严重时出租车订单量减少,平均出行里程攀升,然后疫情好转,出租车订单量增大,平均出行里程回落。
通过 Excel 进行数据分析
有了 MDX for Kylin 的帮助,我们在 Excel 中也可以连接 Kylin 进行大数据分析。这次测试中,我们使用本地 windows 机器上的 Excel 连接 MDX for Kylin 进行演示。
1.打开 Excel,选择 数据 -> 获取数据 -> 来自数据库 -> 自 Analysis Services:
2.在数据连接向导中填写MDX for Kylin 连接信息,服务器名称为 http://${kylin_node_public_ip}:7080/mdx/xmla/covid_trip_project:
3.然后为当前的数据连接创建数据透视表,在数据透视表字段中,我们可以看到,在 Excel 中连接 MDX for Kylin 中的 dataset 获取数据信息,可以与 Tableau 保持完全一致,无论分析人员是在 Tableau 还是 Excel 中进行分析,都是在一致的数据模型、维度和业务指标的基础上,达到统一语义的效果。
4.在 Tableau 中我们对 covid19 和 newyork_trip_data 两个数据集进行了疫情地图绘制和趋势分析。在 Excel 中对于同样的数据集和数据场景,我们可以查看更多的明细数据。
- 对于疫情数据,为数据透视表选取地区层级字段
REGION_HIERARCHY,以及事先定义好的新增病例数总和SUM_NEW_POSITIVE_CASES和病死率指标CFR_COVID19:
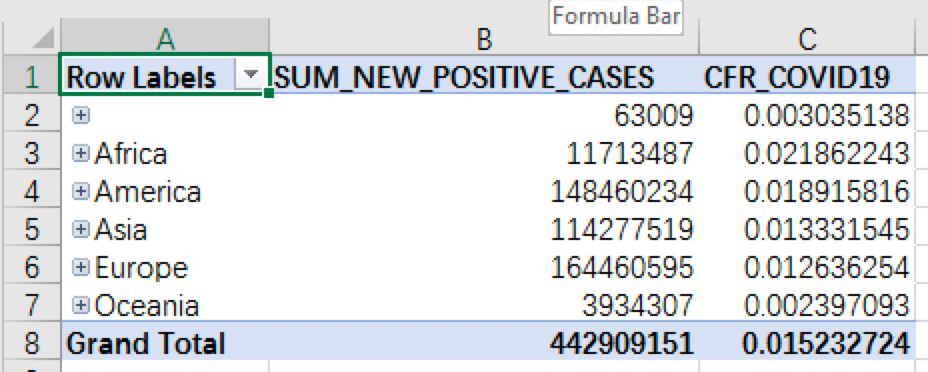
由于地区层级的最上层为 CONTINENT_NAME,所以默认展示洲级别的确诊人数和病死率,可以看到确诊人数最多的洲是欧洲,病死率最高的是非洲。在这张数据透视表中我们可以方便的下钻到更下层的地区级别查看更细粒度的明细数据,比如查看亚洲国家的疫情数据,并根据确诊人数进行降序排序:
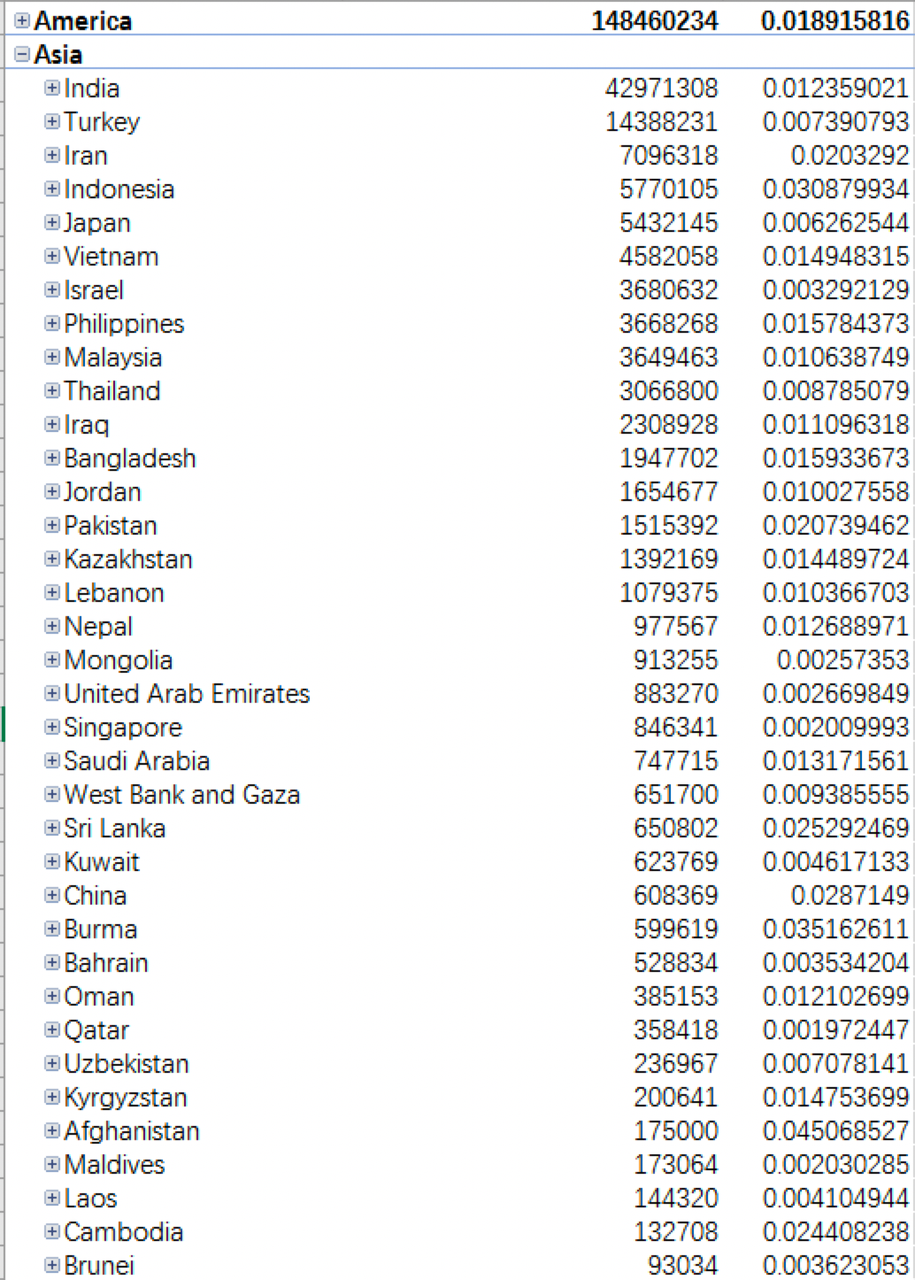
数据显示,亚洲国家中确诊人数排名前三的国家分别是印度、土耳其和伊朗。
- 对于纽约市出租车订单数据,针对 “疫情对于出租车订单数量有无明显影响” 的问题,首先从年份的维度上查看出租车订单数量的年累计和增速,新建透视表选择时间层级维度
TIME_HIERARCHY、YOY_ORDER_COUNT和YTD_ORDER_COUNT:
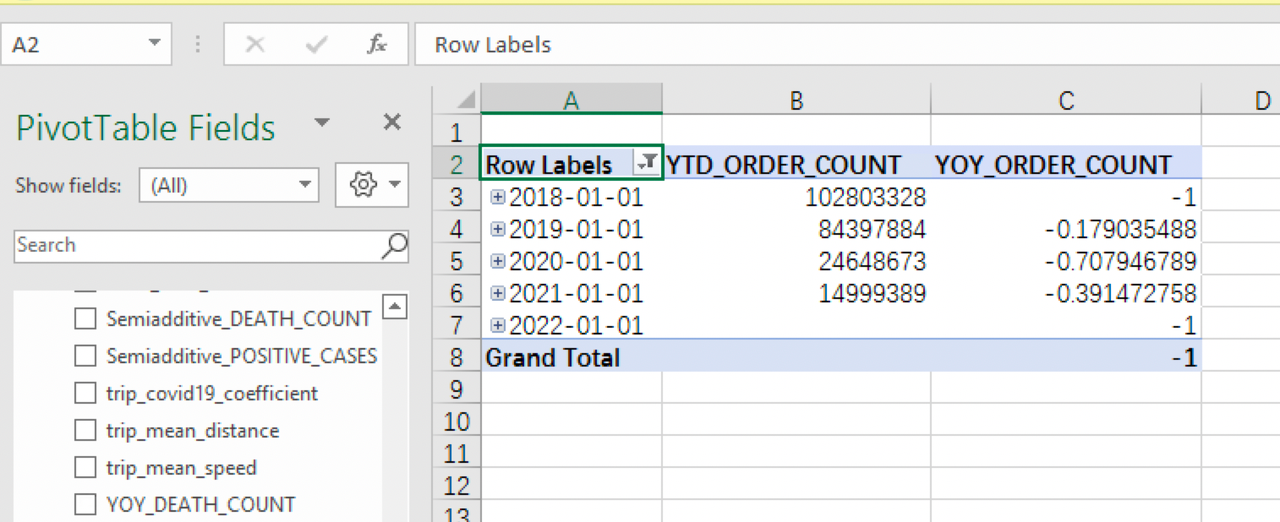
可以看到,2020 年疫情爆发导致出租车订单数量急剧减少,2020年订单量增速为 -0.7079,减少了 70% 的出行订单,2021 年订单量增速仍为负数,但是相比 2020 年疫情初期订单量减少速度放缓了许多。
展开时间层级,可以查看季度级别、月级别直到天级别的订单累计值,选择 MOM_ORDER_COUNT 和 ORDER_COUNT 到透视表中还可以同时查看月度订单增速以及各个时间层级的订单数量:

2020 年 3 月份,订单增速为 -0.52,出租车订单已经出现明显减少,4 月份更是跌至 -0.92,减少了 90% 的订单,后期开始慢慢增长,但是也始终远低于疫情之前的数量。
通过 API 集成 Kylin 到数据分析平台
除了 Excel、Tableau 这种商业 BI 工具,很多企业内部会开发自己的数据分析平台,在这类自研数据分析平台上,用户仍然可以通过调用 API 的方式将 Kylin + MDX for Kylin 作为分析平台的基础底座,保证统一的数据口径。在这次演示中,我们将展示如何通过 Olap4j 向 MDX for Kylin 发送查询,获得分析结果,Olap4j 是一个与 JDBC 驱动类似,能够访问任意 OLAP 服务的 Java 库。
我们提供了一个简单的 demo 可以方便用户直接进行测试,源码位于 mdx query demo:
1.下载 demo 演示相关 jar 包:
wget https://s3.cn-north-1.amazonaws.com.cn/public.kyligence.io/kylin/kylin_demo/mdx_query_demo.tgz
tar -xvf mdx_query_demo.tgz
cd mdx_query_demo
2.运行 demo
运行 demo 之前保证运行环境安装了 java8:

运行 demo 需要两个参数,mdx 节点的 ip 和 需要运行的 mdx 查询,端口默认为 7080,这里的 mdx 节点 ip 就是 kylin 节点的 public ip:
java -cp olap4j-xmla-1.2.0.jar:olap4j-1.2.0.jar:xercesImpl-2.9.1.jar:mdx-query-demo-0.0.1.jar io.kyligence.mdxquerydemo.MdxQueryDemoApplication "${kylin_node_public_ip}" "${mdx_query}"
如果用户在运行 demo 时没有通过命令行输入需要执行的 mdx 语句,则会默认执行以下 mdx 语句统计从出发街区的维度上各个街区的订单数量和平均里程:
SELECT
{[Measures].[ORDER_COUNT],
[Measures].[trip_mean_distance]}
DIMENSION PROPERTIES [MEMBER_UNIQUE_NAME],[MEMBER_ORDINAL],[MEMBER_CAPTION] ON COLUMNS,
NON EMPTY [PICKUP_NEWYORK_ZONE].[BOROUGH].[BOROUGH].AllMembers
DIMENSION PROPERTIES [MEMBER_UNIQUE_NAME],[MEMBER_ORDINAL],[MEMBER_CAPTION] ON ROWS
FROM [covid_trip_dataset]
在这次演示中我们直接执行默认查询,执行成功之后,经过简单处理的查询结果会输出到命令行:

可以看到,运行 Demo 之后成功获得了需要查询的数据,数据结果显示,从 Manhattan 出发的出租车订单数量最多,订单平均里程只有大约 2.4 英里,符合 Manhattan 地理面积小且人口稠密的特点;而从 Bronx 的订单平均里程达到 33 英里,成倍的高于其他任何街区,可能是由于 Bronx 地处偏僻的缘故。
与 Tableau 和 Excel 相同,在 Demo 中编写的 mdx 语言中可以直接使用在 Kylin 以及 MDX for Kylin 中定义的指标。在企业自研数据分析平台中,用户可以对查询返回的数据结果进行进一步分析,根据展示需求生成报表。
统一的数据口径
通过以三种不同的数据分析方式连接 Kylin + MDX for Kylin 进行数据分析展示,我们可以发现,借助 Kylin 多维数据库和 MDX for Kylin 语义层功能,无论用户在业务场景中使用哪种方式分析数据,都可以使用相同的数据模型和业务指标,达到统一数据口径的目的。
销毁集群
销毁查询集群
在上述分析完成之后,我们可以执行集群销毁命令来销毁查询集群。如果用户希望同时销毁 Kylin 以及 MDX for Kylin 的元数据库 RDS、监控节点以及 VPC,那么可以执行集群销毁命令:
python deploy.py --type destroy-all
检查 AWS 资源
在销毁所有集群资源后,CloudFormation 中不会保留与部署工具相关的任何 Stack。如果用户想要删除 S3 中与部署工具相关的文件以及数据,可以手动删除 S3 工作目录下的以下文件夹:
总结
通过这次演示教程,只需要一个 AWS 账号,用户就可以使用云上部署工具,借助于 Kylin 的预计算技术和多维模型,以及MDX for Kylin 的基础指标管理,快速且方便的搭建基于 Kylin + MDX for Kylin 的云上大数据分析平台,对接各种 BI 工具进行技术验证,达到降本增效、统一数据口径的目的。