
Kylin on Cloud —— 两小时快速搭建云上数据分析平台(上)
背景
Apache Kylin 是基于预计算和多维模型的多维数据库,支持 SQL 标准查询接口,在 Kylin 中用户可以通过创建 Model 定义表关系,通过创建 Cube 定义维度和度量,然后构建 Cube 对需要聚合的数据进行预计算,将预计算好的数据保存起来,用户执行查询时便可以直接在经过预计算的数据上进行进一步的聚合或者直接返回查询结果,成倍提升查询效率。
随着 Kylin 4.0 新架构的版本发布与更新,Kylin 具备了在脱离 Hadoop 的云环境下进行集群部署的能力;为了使用户能够轻松地在云上部署 Kylin,Kylin 社区又于近日开发了云上部署工具,用户使用部署工具只需执行一行命令便可以得到一个完备的 kylin 集群,获得高效快速的分析体验;2022 年1月份,Kylin 社区发布了 mdx for kylin 来加强 Kylin 作为多维数据库的业务表达能力,MDX for Kylin 提供了 MDX 的查询接口,mdx for kylin 可以在 Kylin 已经定义好的多维模型的基础上更进一步的创建业务指标,将 Kylin 中的数据模型转换为业务友好的语言,赋予数据业务价值,方便对接 Excel、Tableau 等 BI 工具进行多维分析。
基于以上一系列的技术支撑,用户不仅可以方便快捷的在云上部署 Kylin 集群,创建多维模型,体验经过预计算的快速查询响应,还能够结合 MDX for Kylin 对业务指标进行定义和管理,将 DW 技术层提升到业务语义层。
用户可以在 Kylin + MDX for Kylin 之上直接对接 BI 工具进行多维数据分析,也可以以此为底座建设指标平台等复杂应用。相比于直接基于 Spark、Hive 等在运行时进行 Join 和聚合查询的计算引擎之上构建指标平台,利用 Kylin 可以依托于多维模型和预计算技术,以及 mdx for kylin 的语义层能力,满足指标平台所需要的海量数据计算、极速查询响应、统一的多维模型、对接多种 BI、基础的业务指标管理等多种关键功能。
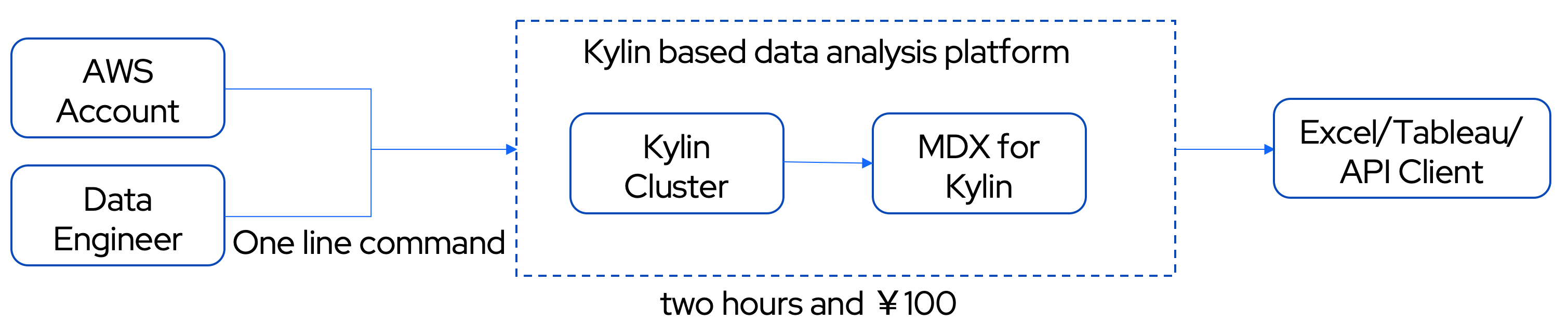
本文的以下部分将会带领读者,从一个数据工程师的角度,快速体验在云上搭建基于 Kylin 的数据分析平台(Kylin on Cloud),在亿行级数据之上获得高性能低成本的查询体验,并通过 mdx for kylin 管理业务指标,直接对接 BI 工具快速生成报表。
本教程每一个步骤都有详细说明,并附有配图和检查点,帮助新手上路。读者只需要准备一个 AWS 账号,预计这个过程需要大约 2 小时,花费 ¥100 左右。
业务场景
自 2020 年初以来 COVID-19 在全世界范围内快速传播,对人们的衣食住行尤其是出行习惯造成极大影响。这次数据分析结合 COVID-19 疫情数据和 2018 年以来纽约出租车出行数据,通过分析疫情指标和各种出行指标,比如确诊人数、病死率、出租车订单数、平均出行距离等,来洞察纽约市出租车行业受疫情影响的变化趋势,以支撑决策。
业务问题
- 多指标联合分析各个国家地区疫情严重程度
- 纽约市各个街区出行指标对比,比如订单数数量、出行里程等
- 疫情对于出租车订单数量有无明显影响
- 疫情之后的出行习惯变化,更偏向远程出行还是近程
- 疫情严重程度与出租车出行次数是否强相关
数据集
COVID-19 数据集
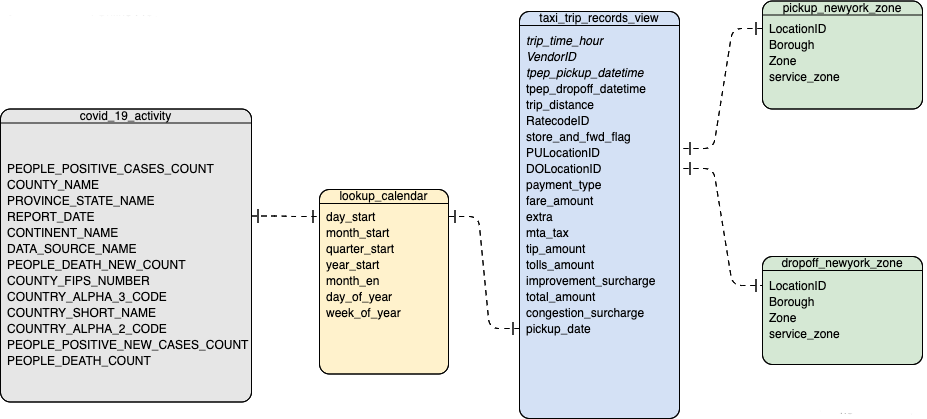
COVID-19 数据集包括一张事实表 covid_19_activity 和一张维度表 lookup_calendar。
其中,covid_19_activity 记录每一天全球范围内不同地区的确诊和死亡数字;lookup_calendar 为日期维度表,保存了时间的扩展信息,比如每一个日期对应的年始、月始等,covid_19_activity 和 lookup_calendar 之间通过日期进行关联。
COVID-19 数据集相关信息如下:
| 数据大小 | 235 MB |
| 事实表数据行数 | 2,753,688 |
| 数据日期 | 2020-01-21~2022-03-07 |
| 数据集提供方下载地址 | https://data.world/covid-19-data-resource-hub/covid-19-case-counts/workspace/file?filename=COVID-19+Activity.csv |
| 数据集 S3 地址 | s3://public.kyligence.io/kylin/kylin_demo/data/covid19_data/ |
纽约市出租车订单数据集
纽约市出租车订单数据集包括一张事实表 taxi_trip_records_view 和两张维度表 newyork_zone、lookup_calendar。
其中,taxi_trip_records_view 中的一条记录对一次出租车出行,记录了出发地点 ID、到达地点 ID、出行时长、订单金额、出行距离等;newyork_zone 记录了地点 ID 所对应的行政区等信息,taxi_trip_records_view 分别通过 PULocationID 和 DOLocationID 两个列与 newyork_zone 建立关联关系,统计出发街区和到达街区信息;lookup_calendar 与 COVID-19 数据集中的维度表为同一张表,taxi_trip_records_view 与 lookup_calendar 通过日期进行关联。
纽约市出租车订单数据集相关信息如下:
| 数据大小 | 19 G |
| 事实表数据行数 | 226,849,274 |
| 数据日期 | 2018-01-01~2021-07-31 |
| 数据集提供方下载地址 | https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page |
| 数据集 S3 地址 | s3://public.kyligence.io/kylin/kylin_demo/data/trip_data_2018-2021/ |
ER 关系图
新冠疫情数据集和纽约市出租车订单数据集的 ER 关系图如下图所示:
指标设计
针对需要分析的业务场景和业务问题,我们设计了以下原子指标和业务指标:
1.原子指标
原子指标指的是在 Kylin Cube 中创建的各种度量,它们通常是在单一列上面进行聚合计算,相对比较简单。
- Covid19 病例数 sum(covid_19_activity.people_positive_cases_count)
- Covid19 病死数 sum(covid_19_activity. people_death_count)
- 新增 Covid19 病例数 sum(covid_19_activity. people_positive_new_cases_count)
- 新增 Covid19 病死数 sum(covid_19_activity. people_death_new_count)
- 出租车出行里程 sum(taxi_trip_records_view. trip_distance)
- 出租车订单交易额 sum(taxi_trip_records_view. total_amount)
- 出租车出行数量 count()
- 出租车出行时长 sum(taxi_trip_records_view.trip_time_hour)
2.业务指标
业务指标是指基于原子指标定义的各种复合运算,具有具体的业务含义。
- 各原子指标的月累计MTD、年累计YTD
- 各原子指标的月增速MOM、年增速YOY
- Covid19 病死率:死亡人数/确诊人数
- 出租车平均出行速度:出租车出行里程/出租车出行时间
- 出租车出行平均里程:出租车出行里程/出租车出行数量
操作步骤概览
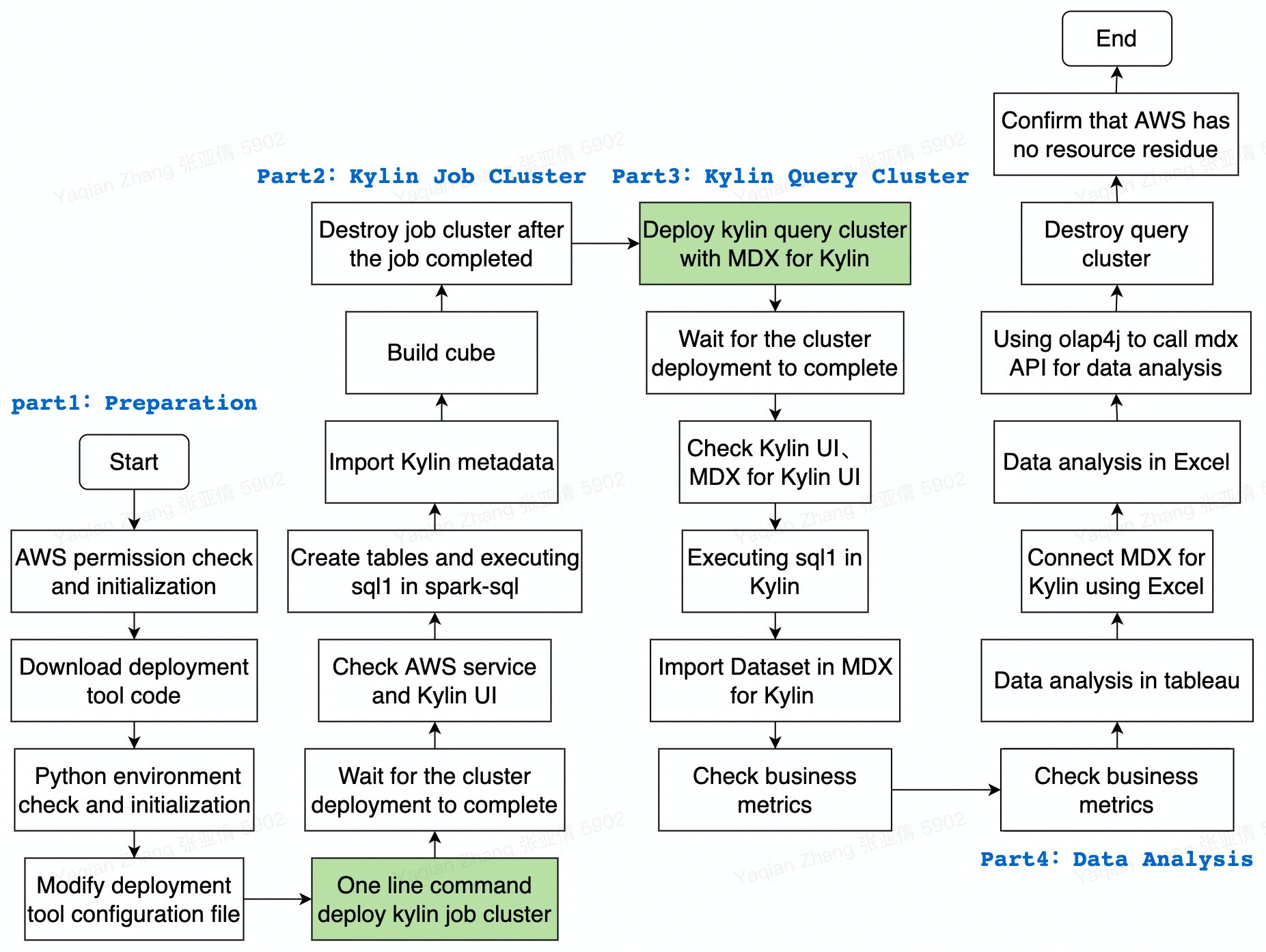
搭建基于 Apache Kylin 的云上数据分析平台并进行数据分析的主要操作步骤如下图:
集群架构
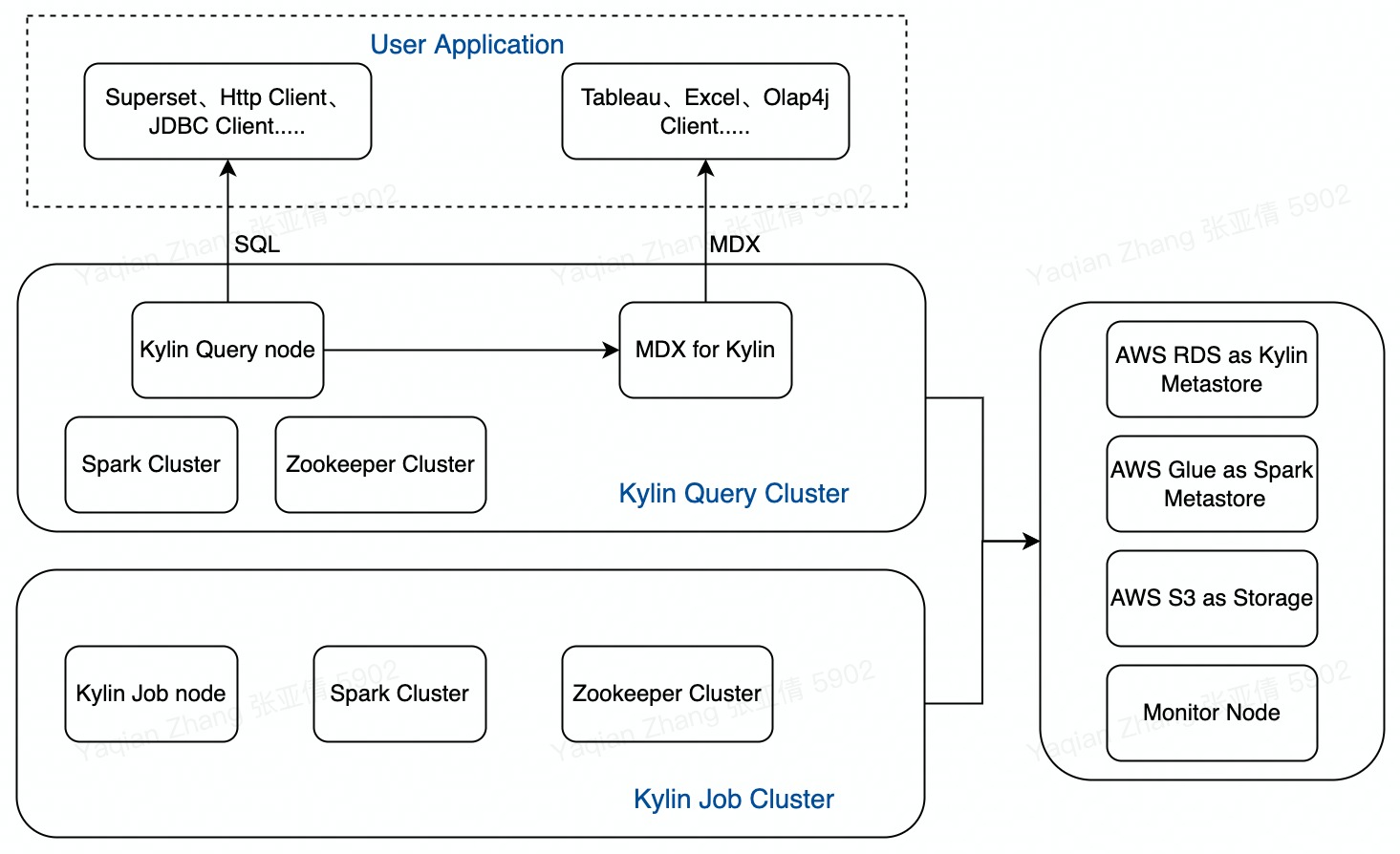
使用云上部署工具部署出的 Kylin 集群架构如图所示:
Kylin on Cloud 部署
环境要求
- 需要本地机器已安装 git,用于下载部署工具代码;
- 需要本地机器已安装 Python 3.6.6 及以上版本,用于运行部署工具。
AWS 权限检查与初始化
登录 AWS 账号,根据 准备文档 来检查用户权限、创建部署工具需要的 Access Key、IAM Role、Key Pair 和 S3 工作目录。后续的 AWS 操作都会以这个帐号的身份执行。
配置部署工具
1.执行下面的命令获得 Kylin on AWS 部署工具的代码
git clone -b kylin4_on_cloud --single-branch https://github.com/apache/kylin.git && cd kylin
2.在本地机器初始化 python 虚拟环境
检查 python 环境,需要 Python 3.6.6 以上:
python --version
初始化 python 虚拟环境,安装依赖:
bin/init.sh
source venv/bin/activate
3.修改配置文件 kylin_configs.yaml
打开部署工具代码中的 kylin_configs.yaml,将文件中的配置项替换为实际值:
AWS_REGION: EC2 节点位置 Region,默认为 cn-northwest-1${IAM_ROLE_NAME}: 提前创建的 IAM Role 名称,比如 kylin_deploy_role${S3_URI}: 用于部署 kylin 的 S3 工作目录,比如 s3://kylindemo/kylin_demo_dir/${KEY_PAIR}: 提前创建的 Key pairs 名字,比如 kylin_deploy_key${Cidr Ip}: 允许访问 EC2 实例的 IP 地址范围,比如 10.1.0.0/32,通常设为您的外网 IP 地址,确保创建的 EC2 实例只有您能访问
出于读写分离隔离构建和查询资源的考虑,在以下的步骤中会先启动一个构建集群用于连接 Glue 建表、加载数据源、提交构建任务进行预计算,然后销毁构建集群,保留元数据,启动带有 MDX for Kylin 的查询集群,用于创建业务指标、连接 BI 工具执行查询,进行数据分析。Kylin on AWS 集群使用 RDS 存储元数据,使用 S3 存储构建后的数据,并且支持从 AWS Glue 中加载数据源,除了 EC2 节点之外使用的资源都是持久化的,不会随着节点的删除而消失,所以在没有查询或者构建任务时,用户可以随时销毁构建或查询集群,只要保留元数据、S3 工作目录即可。
Kylin 构建集群
启动 Kylin 构建集群
1.通过如下命令启动构建集群。根据网络情况不同,部署启动可能需要 15-30 分钟。
python deploy.py --type deploy --mode job
2.构建集群部署成功后,命令窗口可以看到如下输出:

检查 AWS 服务
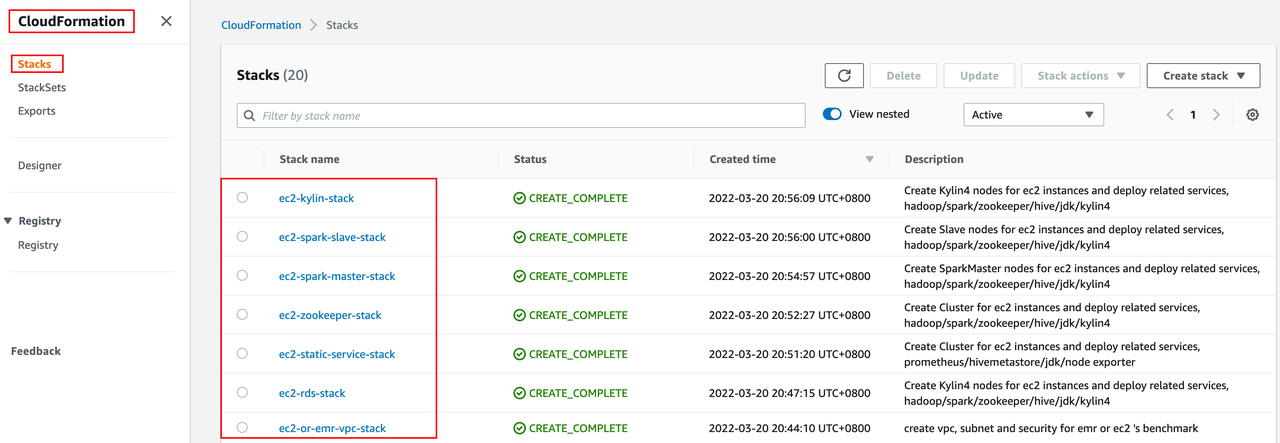
1.进入 AWS 控制台的 CloudFormation 界面,可以看到 Kylin 部署工具一共起了 7 个 stack:
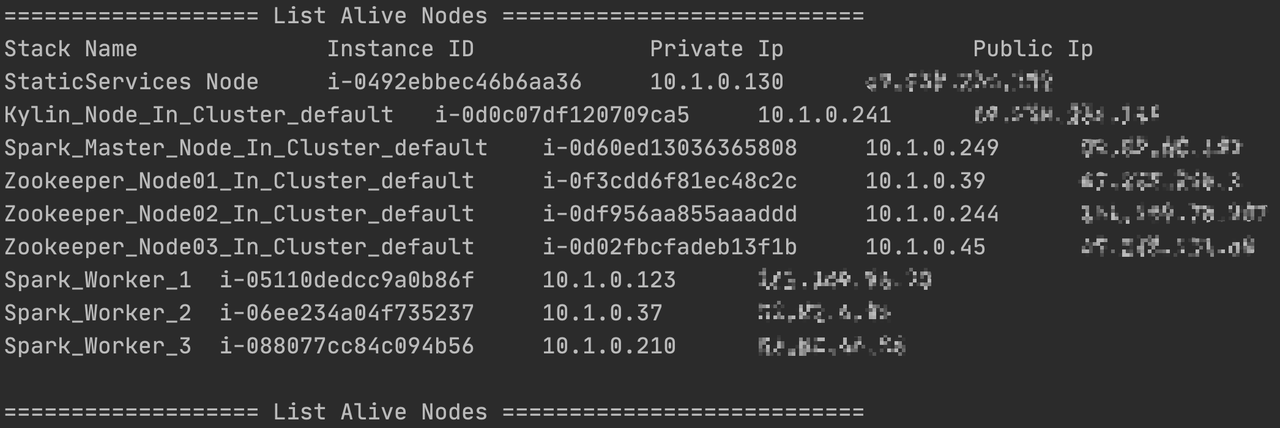
2.用户可以通过 AWS 控制台查看 EC2 节点的详细信息,也可以在命令行界面使用如下命令列出所有 EC2 节点的名字、私有 IP 和公有 IP:
python deploy.py --type list
体验 spark-sql 原生查询速度
为了直观的感受到预计算给查询性能带来的提升,在构建 cube 之前,我们先在 spark-sql 中体验原生的查询速度:
1.首先,我们通过 kylin 节点的公有 IP 登录到该 kylin 所在的 EC2 机器,并切换到 root 用户,执行 ~/.bash_profile 使提前设置的环境变量生效:
ssh -i "${KEY_PAIR}" ec2-user@${kylin_node_public_ip}
sudo su
source ~/.bash_profile
2.然后进入 $SPARK_HOME 并修改配置文件 conf/spark-defaults.conf,将 spark_master_node_private_ip 修改为 spark master 节点的私有 IP:
cd $SPARK_HOME
vim conf/spark-defaults.conf
# 将 spark_master_node_private_ip 替换为真实 spark master 节点的私有ip
spark.master spark://spark_master_node_private_ip:7077
spark-defaults.conf 中关于 driver 和 executor 的资源配置与 kylin 查询集群的资源配置是一致的。
3.在 spark-sql 中建表
测试所用数据集的所有数据存放在位于 cn-north-1 和 us-east-1 地区的 S3 bucket 中,如果你的 S3 bucket 位于 cn-north-1 或者 us-east-1,那么你可以直接执行建表 sql;否则需要执行以下脚本复制数据到 kylin_configs.yaml 中设置的 S3 工作目录下,并修改建表 sql:
## AWS CN 用户
aws s3 sync s3://public.kyligence.io/kylin/kylin_demo/data/ ${S3_DATA_DIR} --region cn-north-1
## AWS Global 用户
aws s3 sync s3://public.kyligence.io/kylin/kylin_demo/data/ ${S3_DATA_DIR} --region us-east-1
# 修改建表 sql
sed -i "s#s3://public.kyligence.io/kylin/kylin_demo/data/#${S3_DATA_DIR}#g" /home/ec2-user/kylin_demo/create_kylin_demo_table.sql
执行建表 sql:
bin/spark-sql -f /home/ec2-user/kylin_demo/create_kylin_demo_table.sql
4.在 spark-sql 中执行查询
进入 spark-sql:
bin/spark-sql
在 spark-sql 中执行查询:
use kylin_demo;
select TAXI_TRIP_RECORDS_VIEW.PICKUP_DATE, NEWYORK_ZONE.BOROUGH, count(*), sum(TAXI_TRIP_RECORDS_VIEW.TRIP_TIME_HOUR), sum(TAXI_TRIP_RECORDS_VIEW.TOTAL_AMOUNT)
from TAXI_TRIP_RECORDS_VIEW
left join NEWYORK_ZONE
on TAXI_TRIP_RECORDS_VIEW.PULOCATIONID = NEWYORK_ZONE.LOCATIONID
group by TAXI_TRIP_RECORDS_VIEW.PICKUP_DATE, NEWYORK_ZONE.BOROUGH;
然后可以看到,在资源与 kylin 查询集群配置相同的情况下,使用 spark-sql 直接查询耗时超过100s:

5.查询执行成功后必须退出 spark-sql 再进行下面的步骤,防止占用资源。
导入 Kylin 元数据
1.进入 $KYLIN_HOME
cd $KYLIN_HOME
2.导入元数据
bin/metastore.sh restore /home/ec2-user/meta_backups/
3.重载元数据
根据 EC2 节点的公有 IP,在浏览器输入 http://${kylin_node_public_ip}:7070/kylin 进入 kylin web 页面,并使用 ADMIN/KYLIN 的默认用户名密码登录:
通过 System -> Configuration -> Reload Metadata 重载 Kylin 元数据:
如果用户想要了解如何手动创建 Kylin 元数据中所包含的 Model 和 Cube,可以参考:(Create model and cube in kylin)[https://cwiki.apache.org/confluence/display/KYLIN/Create+Model+and+Cube+in+Kylin]。
执行构建
提交 cube 构建任务,由于在 model 中未设置分区列,所以这里直接对两个 cube 进行全量构建:

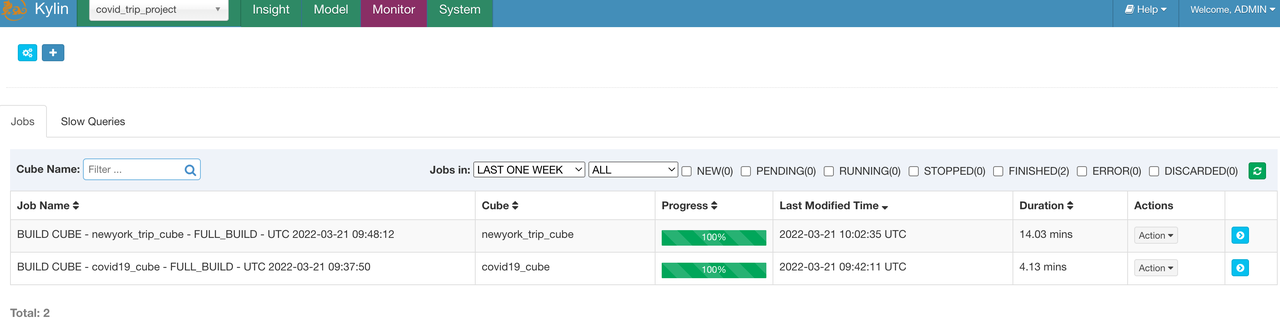
销毁构建集群
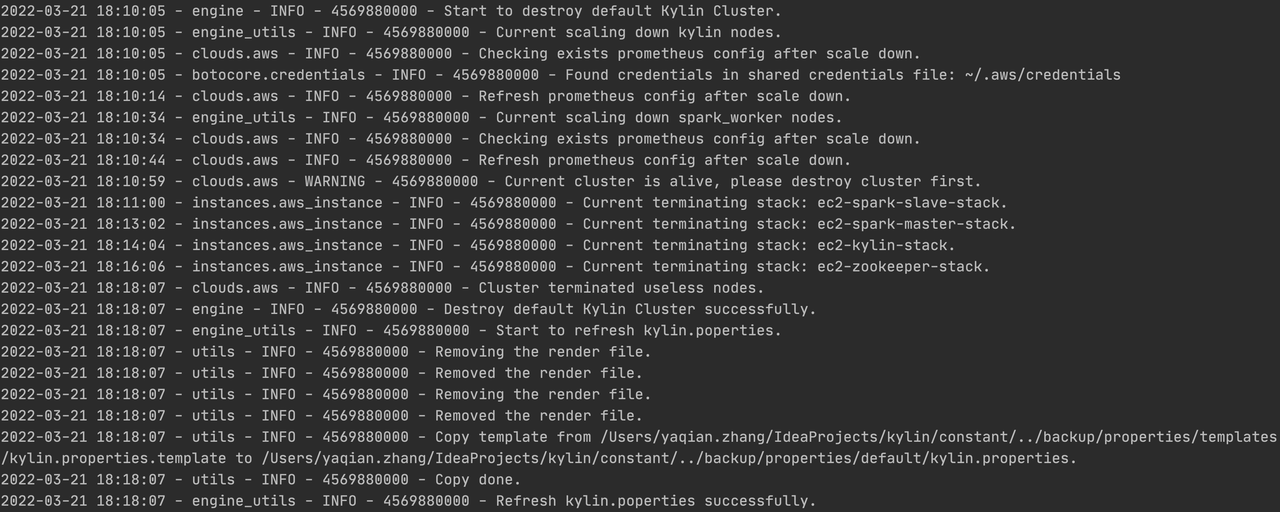
构建完成之后,执行集群销毁命令销毁构建集群,默认情况下会保留 RDS stack、monitor stack 和 vpc stack:
python deploy.py --type destroy
集群销毁成功:
检查 AWS 资源
集群销毁成功后,可以到 AWS 控制台的 CloudFormation 服务确认是否存在资源残留,由于默认会保留元数据 RDS、监控节点和 VPC 节点,所以集群销毁后 CloudFormation 页面还会存在以下三个 Stack:
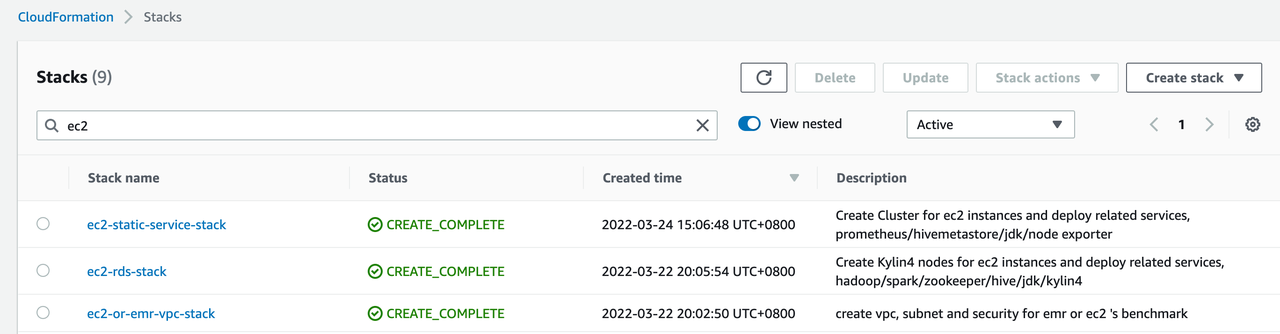
下面启动查询集群时仍然会使用这三个 Stack 中的资源,这样我们可以保证查询集群和构建集群使用同一套元数据。
以上部分为 Kylin on Cloud —— 两小时快速搭建云上数据分析平台 的上篇,下篇请查看:Kylin on Cloud —— 两小时快速搭建云上数据分析平台(下)