
下一代 Kylin:更强大和易用的 OLAP
01 Apache Kylin 的今天
目前,Apache Kylin 的最新发布版本是 4.0.1。 Apache Kylin 4.0 是 Kylin 3.x(HBase Storage)版本后的一次重大版本更新,Kylin 4 使用 Parquet 这种真正的列式存储来代替 HBase 存储,从而提升文件扫描性能;同时,Kylin 4 重新实现了基于 Spark 的构建引擎和查询引擎,使得计算和存储的分离变为可能,更加适应云原生的技术趋势。
Kylin 4.0 对构建和查询引擎做了全面更新,实现了去 Hadoop 部署,解决了初步上云的问题。除此之外,结合社区用户的反馈以及 OLAP 技术发展的趋势,Kylin 社区发现当前的 Kylin 仍然存在一些弱势与不足,比如业务语义层能力有待加强、预计算模型变更不够灵活等,基于这些不足可以将后续需要进行的工作总结为以下几个方面:
- 对非技术人员友好的多维查询能力。多维模型是 Kylin 区别于一般 OLAP 引擎的关键。特点在于,以维度、度量为基础的模型概念对非技术人员更友好,更接近 “人人都是数据分析师” 的目标。非技术人员能用的多维查询能力,应该是 Kylin 技术后续的新重心。
- Native Engine。Kylin 引擎在向量加速、指令级优化方面尚有很大的提升空间。Kylin 依赖的 Spark 社区也有很强的 Native Engine 需求,乐观估计,Native Engine 可以至少提升目前的 Kylin 3 倍以上性能,值得投入。
- 更多云原生能力。Kylin 4.0 只完成了初步上云,实现了云上的快速部署、动态资源伸缩等功能,但仍有很多云原生的能力还有待开发。
02 Apache Kylin 的定位 —— 多维数据库
Kylin 的核心是一个多维数据库,是一种特殊的 OLAP 引擎。虽然从诞生以来,Kylin 一直都有关系数据库的能力,也常常与其他关系型 OLAP 引擎做对比,但真正让 Kylin 与众不同的是它的多维模型和多维数据库能力。考虑到 Kylin 的本质和未来广泛的业务用途(不仅是技术用途),我们将明确定位 Kylin 为一个多维数据库。我们也期望通过多维模型和预计算技术,Apache Kylin 能让普通人看得懂和用得起大数据,最终实现数据民主化。
语义层
多维数据库与关系型数据库的 关键区别在于业务表达能力。尽管 SQL 表达能力很强,是数据分析师的基本技能,但如果以 “人人都是分析师” 为目标,SQL 和关系数据库对非技术人员还是太难了。从非技术人员的视角,数据湖和数据仓库就好似一个黑暗的房间,知道其中有很多数据,却因为不懂数据库理论和 SQL,无法看清、理解、和使用这些数据。
如何让数据湖(和数据仓库)对非技术人员也 “清澈见底”?这就需要引入一个对非技术人员更加友好的数据模型 – 多维数据模型。如果说关系模型描述了数据的技术形态,那么多维模型则描述了数据的业务形态。在多维数据库中,度量对应了每个人都懂的业务指标,维度则是比较、观察这些业务指标的角度。要与上个月比较 KPI,要在平行事业部之间比较绩效,这些是每个非技术人员都理解的概念。通过将关系模型映射到多维模型,本质是在技术数据之上增强了业务语义,形成业务语义层,帮助非技术人员也能看懂、探索、使用数据。
为了增强 Kylin 作为多维数据库的语义层能力,支持多维查询语言是 Kylin Roadmap 上的重点内容,比如 MDX 和 DAX。通过 MDX 可以将 Kylin 中的数据模型转换为业务友好的语言,赋予数据业务价值,方便对接 Excel、Tableau 等 BI 工具进行多维分析。
预计算和灵活的模型
继续通过预计算技术降低单查询成本,让普通人用得起大数据,也是 Kylin 不变的使命。如果说多维模型解决了非技术人员看得懂数据的问题,那么预计算则能解决普通人用得起数据的问题,两者都是数据民主化的必备条件。通过一次计算多次使用,数据成本可以被多个用户分摊,达到用户越多越便宜的规模效应。预计算是 Kylin 的传统强项,但是在预计算模型的变更方面缺乏一定的灵活性,为了加强 Kylin 的模型的灵活变更能力,并带来更多可优化的空间,Kylin 社区预计在未来的 Kylin 中提出全新的元数据结构,使预计算更灵活,能够应对随时可能发生变化的表结构或者业务需求。
总结
综上,我们将明确 Kylin 的技术定位是一个多维数据库,通过多维模型和预计算技术,让普通人看得懂和用得起大数据,最终实现数据民主化的美好愿景。同时,对于今天将 Kylin 用作 SQL 加速层的用户,Kylin 将继续保有完备的 SQL 接口,保证预计算技术可以同时被关系模型和多维模型使用。
在下图中,我们能清晰地看到未来 Kylin 关注的方向,新增和修改的部分大致使用蓝色和橙色标示出来。
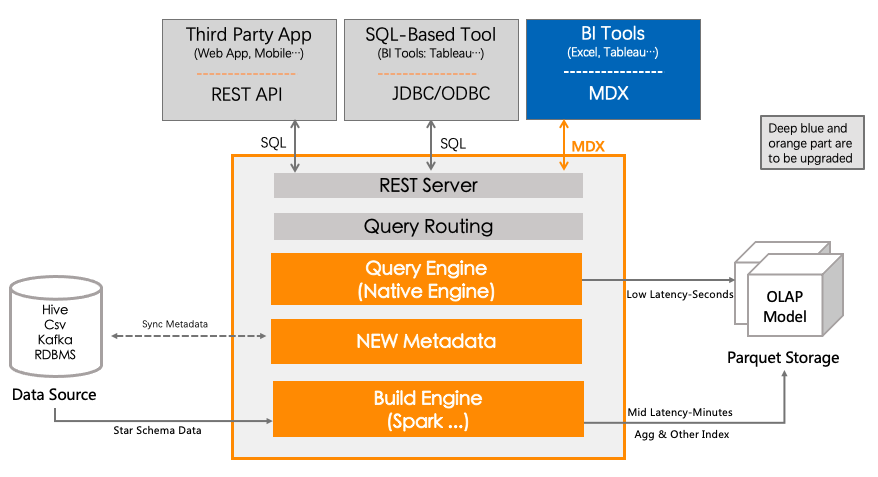
03 Apache Kylin 升级计划
基于 Kylin 作为一个多维数据库的定位,结合当前 Kylin 存在的有待加强的能力,同时为了支持 Schema Change 等用户期待已久的功能,我们计划在未来的 Kylin 中引入新的 DataModel 的元数据结构,不再向用户暴露 Cube 的元数据,将元数据依赖关系简化为 Model -> Table 。
由于元数据是社区后续协作开发的基础和契约,全新元数据结构的设计开发将会是当前以及今后几个月内 Kylin 社区工作的重点,元数据设计以及讨论文档会在一个月内发布,欢迎大家踊跃参与讨论,不出意外地话 2022 年新的元数据结构就会与大家见面,敬请期待。
除了元数据结构升级以外,和元数据升级配套的构建和查询引擎、语义层能力(MDX)、与 BI 工具更好集成、Native Engine 等也是 Kylin 社区一直在积极推进的重点工作,欢迎更多志同道合的小伙伴参与进来,共创社区。
** Further Reading **
- https://en.wikipedia.org/wiki/Data_model
- https://en.wikipedia.org/wiki/Semantic_layer
- https://en.wikipedia.org/wiki/Multidimensional_analysis
- https://en.wikipedia.org/wiki/MultiDimensional_eXpressions
- https://en.wikipedia.org/wiki/XML_for_Analysis
- https://en.wikipedia.org/wiki/SIMD
- https://en.wikipedia.org/wiki/Cloud_native_computing
- https://blogs.gartner.com/carlie-idoine/2018/05/13/citizen-data-scientists-and-why-they-matter/