
Deep dive into Kylin's Real-time OLAP
Preface
At the beginning of Apache Kylin, the main purpose was to solve the need for interactive data analysis on massive data. The data source mainly comes from the data warehouse (Hive), and the data is mostly historical rather than real-time. Streaming data processing is an brand-new field of big data development that requires data to be queried as soon as it enters the system(second latency). Until now (the latest release of v2.6), Apache Kylin’s main capabilities are still in the field of historical data analysis, even the NRT(Near real-time streaming) feature was introduced in v1.6, there are still several minutes of delay, it is difficult to meet real-time query requirements.
To keep up with the trend of big data development, eBay’s Kylin development team (allenma, mingmwang, sanjulian, wangshisan, etc.) Based on Kylin, the Real-time OLAP feature was developed to implement Kylin’s real-time query of Kafka streaming data. This feature has been used in eBay in production env and has been running stably for more than one year. It was contributed to community in the December of 2018.
In this article, we will focus on introducing and analyzing Apache Kylin’s Real-time OLAP feature, usage, benchmarking, etc. In What is Real-time OLAP, we will introduce architecture, concepts and features. In How to use Real-time OLAP, we will introduce the deployment, enabling and monitoring aspects of the Receiver cluster. Finally, in the Real-time OLAP FAQ, we will introduce the answers to some common questions. The meaning of important configuration entry, usage restrictions, and future development plans.
-
What is Real-time OLAP
- The importance of streaming data processing
- Introduction to Real-time OLAP
- Real-time OLAP concepts and roles
- Real-time OLAP architecture
- Real-time OLAP features
- Real-time OLAP metadata
- Real-time OLAP Local Segment Cache
- The status of Streaming Segment and its transformation
- Real-time OLAP build process analysis
- Real-time OLAP query process analysis
- Real-time OLAP Rebalance process analysis
-
How to use Real-time OLAP
- Deploy Coordinator and Receiver
- Configuring Streaming Table
- Add and modify Replica Set
- Design model and cube
- Enable and stop Cube
- Monitor consumption status
- Coordinator Rest API Description
-
Frequently Asked Questions for Real-time OLAP
- There is a “Lambda” checkbox when configuring the Kafka data source. What does it do?
- In addition to the base cuboid, can I build other cuboids on the receiver side?
- How should I scale out my receiver cluster? How to deal with partition increase for Kafka topic?
- What is the benchmark result? What is the approximate length of the query? What is the approximate data ingest rate of a single Receiver?
- Which one is more suitable for my needs than Kylin’s NRT Streaming?
- What are the main limitations of Real-time OLAP? What are the future development plans?
Part-I. What is Real-time OLAP for Kylin
1.1 Streaming Data Processing and Real-time OLAP
For many commercial companies, user messages are analyzed for the purpose of making better business decisions and better market planning. If the message enters the data analysis platform earlier, decision makers can respond faster, reducing time and money waste. Streaming data processing means faster feedback, and decision makers can make more frequent and flexible planning adjustments.
There are various types of data sources in the company, including mobile devices such as servers and mobile phones, and IoT devices. Messages from different sources are often distinguished by different topic and aggregated into a message queue (Message Queue/Message Bus) for data analysis. Traditional data analysis tools use batch tools such as MapReduce for data analysis, which has large data delays, typically hours to days. As you can see from the figure below, the main data latency comes from two processes: extracting from the message queue through the ETL process to the data warehouse, and extracting data from the data warehouse for precomputation to save the results as cube data. Since both of these parts are calculated using batch-compute programs, the calculation take a long time , which make real-time query difficult to achieve. We think to solve the problem, we need to bypass these processes, by building a bridge between data collection and OLAP platforms. Let the data go directly to the OLAP platform.
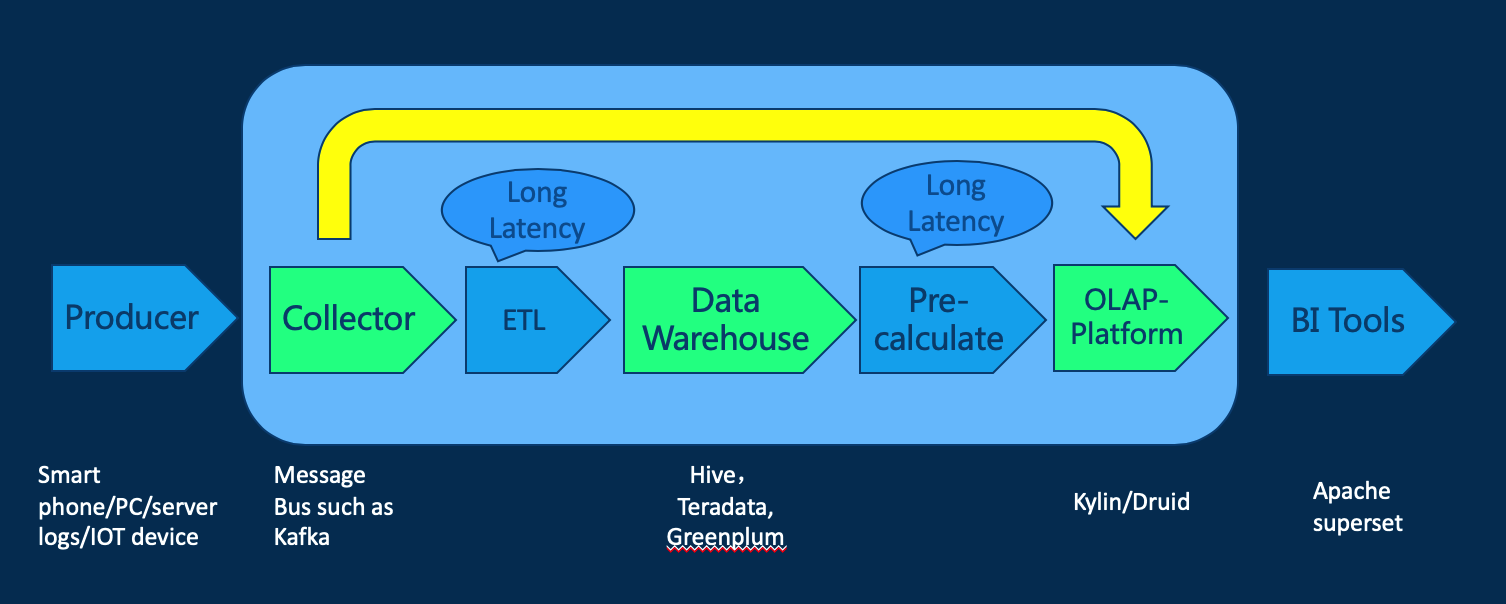
There are already some mature real-time OLAP solutions, such as Druid, that provide lower data latency by combining query results in real-time and historical parts. Kylin has reached a certain level in analyzing massive historical data. In order to take a step toward real-time OLAP, Kylin developers have developed Real-time OLAP.
1.2 Introduction to Real-time OLAP
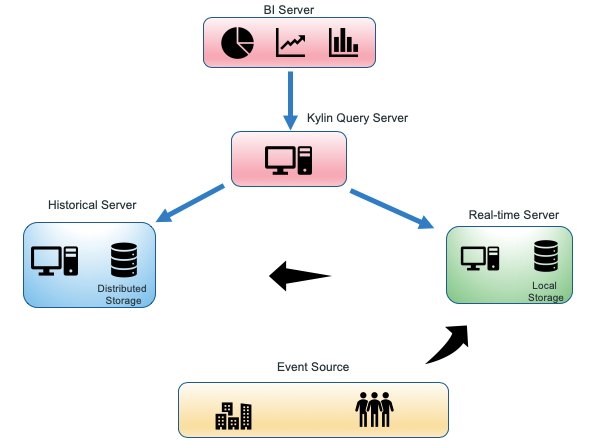
Under the new architecture, the data query request is divided into two parts according to the Timestamp Partition Column. The query request of the latest time period will be sent to the real-time node, and the query request for historical data will still be sent to the HBase region server. Query server needs to merge the results of both and return it to client.
At the same time, the real-time node will continuously upload the local data to the HDFS. When a certain condition is met, the segment will be built by MapReduce, thereby realizing the conversion of the real-time part to the historical part, and achieving the purpose of reducing the pressure of the real-time computing node.
1.3 Concepts and roles of Real-time OLAP
To implement Real-time OLAP, Kylin introduces some new concepts, and here is a preliminary introduction.
-
Streaming Receiver
The role of Streaming Receiver is worker, each receiver is a Java process, managed by Coordinator, which main responsibilities include:- Ingest real-time data;
- Build a cuboid in memory, periodically flush the cuboid data which stored in memory to disk (form a Fragment file);
- Do checkpoint and merge fragment files timely;
- Accept a query request for the partition which it is responsible for;
- When the segment becomes immutable, upload it to HDFS or delete it locally (depending on the configuration);
-
Receiver Cluster
A collection of Streaming Receivers is called a Receiver cluster. -
Streaming Coordinator
As the Master node of the Receiver cluster, the Streaming Coordinator is mainly responsible for managing Receiver, including allocating/de-allocating Kafka topic partitions to specified Replica sets, suspending or restoring consumption, collecting and displaying various statistical indicators (such as message per second). Whenkylin.server.modeis set tostream_coordinator, the process becomes a Streaming Coordinator. The Coordinator only processes metadata and cluster scheduling, and does not consume messages. -
Coordinator Cluster
Multiple Coordinators can exist at the same time to form a Coordinator cluster. In multiple Coordinators, there is only one leader at a time, only the leader can respond to the request, and the rest of the processes are standby/backup. -
Replica Set
A Replica Set is a set of Streaming Receivers that behave identically. Replica Set is the smallest unit of task allocation. All Receivers under one Replica Set do the same work (that is to say, ingest the same set of partitions) and are backups of each other. When there are some Receiver processes in the cluster that are inaccessible, but each Replica Set is guaranteed to have at least one healthy/accessible Receiver, the cluster will still work and return reasonable query results.
In a Replica Set, there will be a Leader Receiver for additional work, and the remaining Receivers will work as followers. -
Streaming Segment
When Receiver ingests a new message and the value of the time partition column of the message is not included in any existing Segment(says you have a new message{"time":"2019-01-01 12:01:02"}, the latest segment is201901011100-201901011200), Receiver will create a new Segment locally, the initial state of this Segment is Active, and interval between the start time and the end time of the Segment is equal to Segment Window, and the timestamp of all time partition columns contains the message between the start time and the end time of this Segment, which will be responsible for this Segment.At the end time for each segment, the segment won’t close immediately. This is for the purpose of waiting late message, but reveicer won’t wait forever. Once meet some condition, the status of the segment will be changed from Active to IMMUTABLE, once in IMMUTABLE state(become IMMUTABLE means close to write).
When segment become IMMUTABLE is decided by a Sliding Window.
For example, we have a streaming segment which segment range start is
2019-01-01 10:00:00, segment range end is2019-01-01 11:00:00(decided bykylin.stream.cube.window). At the moment of2019-01-01 11:00:00, we will have a Sliding Window, which length is decided bykylin.stream.cube.duration. Its default range should be[2019-01-01 11:00:00, 2019-01-01 12:00:00]. Segment will become IMMUTABLE at the end of Sliding Window, so all message no late than one hour will be included.Since it is a Sliding Window, each late message will trigger the movement of sliding window. Saying a message which event time is
2019-01-01 10:50:10, but it is arrived 20 minutes later, at2019-01-01 11:10:00(we call it ingest time), it will make Sliding Window move to[2019-01-01 11:10:00, 2019-01-01 12:10:00].So, looks like the movement won’t stop, we have another config to limit such movement of Sliding Window, that is
kylin.stream.cube.duration.max, the movemen of Sliding Window will be limit wthin the range[2019-01-01 11:00:00, 2019-01-01 23:00:00]by default.- default value of
kylin.stream.cube.windowis 3600 (one hour) - default value of
kylin.stream.cube.durationis 3600 (one hour) - default value of
kylin.stream.cube.duration.maxis 43200 (12 hour)
- default value of
- Retention Policy
When the Segment converted to IMMUTABLE, how the local data of the Segment be processed will be determined by this configuration entry. There are two options before this configuration entry:
- FULL_BUILD When the current Receiver process is the leader of current Replica Set, it uploads the local data file of the Segment to HDFS, and when the upload is successful, Coordinator sets the Segment status to REMOTE_PERSISTED; after che
- PURGE Wait for a certain amount of time and then delete the local data file
If you are only interested in the results of recent data analysis, consider using the PURGE option.
-
Assignment & Assigner
Assignment is a data structure, it is a Map, the key of this Map is the ID of the Replica Set, and the value is the list of Partitions assigned to this Replica Set (in Java language:Map<Integer, List< Partition>>), the following figure is a simple example.
Assignment is very important, it shows which Kafka Topic Partition is responsible for which Replica Set, it is very important to understand how to use Rebalance related API and learn Streaming metadata.
Based on the current number of cluster resources and Topic Partitions, there are different strategies for proper partition allocation. These policies are handled by Assigner. Assigner currently has two implementations, CubePartitionRoundRobinAssigner, DefaultAssigner.

- Checkpoint
Checkpoint is a mechanism that allows Receiver to continue to consume from the last security point after it restarts. Checkpoint enables the re-use of data as much as possible while the receiver is restarted to ensure that data is not lost. There are two main types of Checkpoint, one is local checkpoint and the other is remote checkpoint. The remote checkpoint occurs when the local segment data file is uploaded to HDFS, and the offset information is recorded in the metadata; the local checkpoint is scheduled by the receiver or triggered by the event, the data is flushed to the local, and the offset is recorded in the local file. .
When Receiver launches the Kafka Consumer API, it tries to check the local checkpoint and remote checkpoint to find the latest offset to start spending.
1.4 Real-time OLAP Architecture
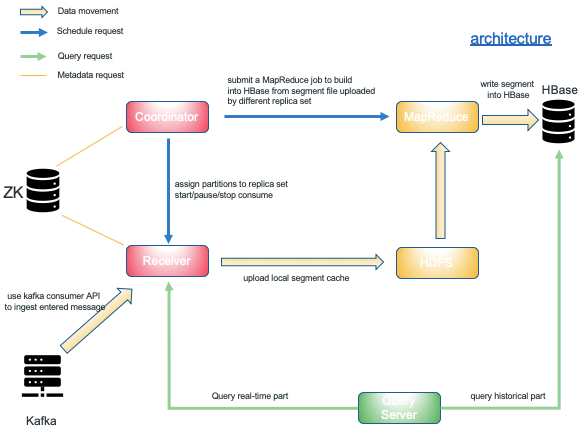
In terms of data flow, we can see that the flow of data is from Kafka to Receiver, then Receiver uploads to HDFS, and finally MapReduce program merges and reprocesses Segment into HBase.
On the query side, the query request is issued by the Query Server, and the request is distributed to both the Receiver and the HBase Region Server based on the time partition column appearing in query.
The assignment of Topic Partition and Rebalance, Segment state management, and job submission are the responsibility of the Coordinator.
1.5 Features of Real-time OLAP
- Once the data is ingested, the cuboid will be calculated in memory immediately.That is to say, data can be queried immediately (milliseconds data delay);
- Automatic data state management and job scheduling;
- According to the query conditions, the query results can include real-time results and historical results;
- The real-time part uses columnar storage and inverted index to speed up queries to reducing query latency;
- A new distributed computing/storage cluster was introduced to Apache Kylin(Receiver Cluster);
- Coordinator and Receiver are highly available.
1.6 Local Segment Cache of Real-time OLAP
The Segment data on the Receiver side consists of two parts: MemoryStore and Fragment File. Inside the MemoryStore, the aggregated data is stored using Map<String[], MeasureAggregator[]>>, where key is an array of strings of dimension values and value is MeasureAggregator array.
As Receiver keeps ingesting messages, when the number of data rows in the MemoryStore reaches threshold (kylin.stream.index.maxrows), a flush will be triggered. The Receiver will flush the entire MemoryStore to disk and form a Fragment File. To read Fragment File, Receiver uses memory-mapped file to speed up the reading. Please refer to source code. In addition, Fragment File uses a variety of methods to optimize scanning and filtering performance, including:
- Compression
- Inverted Index
- Columnar Storage
Finally, Fragment File can be Merge to reduce data redundancy and improve scanning performance.
1.7 Metadata of Real-time OLAP
Real-time OLAP adds some new metadata to Kylin, such as cluster management / topic partition assignment. These data which are currently stored in ZooKeeper (Currently we think streaming metadata are volatile so we didn’t provided method to backup these metadata), including:
- Current Coordinator Leader node
- Receiver node information
- Replica Set information and Replica Set Leader nodes
- Assignment information for Cube
- The build state and upload integrity of the Segment under every Streaming Cube
1.8 State of Streaming Segment and its Conversion
We can express the state transition process of the Segment as the following figure. There are four FIFO queues from left to right. The members of the queue are Segments. Each Segment will go from left to right to the next queue. The queues are
- Active Segment
On the Receiver side, segments which are writable. - Immutable Segment
On the Receiver side, segments that aren’t writable and have not yet been uploaded to HDFS - RemotePersisted Segment
On the Receiver side, it has been uploaded to HDFS, but has not been built into HBase through MapReduce (only available on Replica Set Leader) - Ready Segment
Segments which have entered HBase through MapReduce and removed in Receiver side.
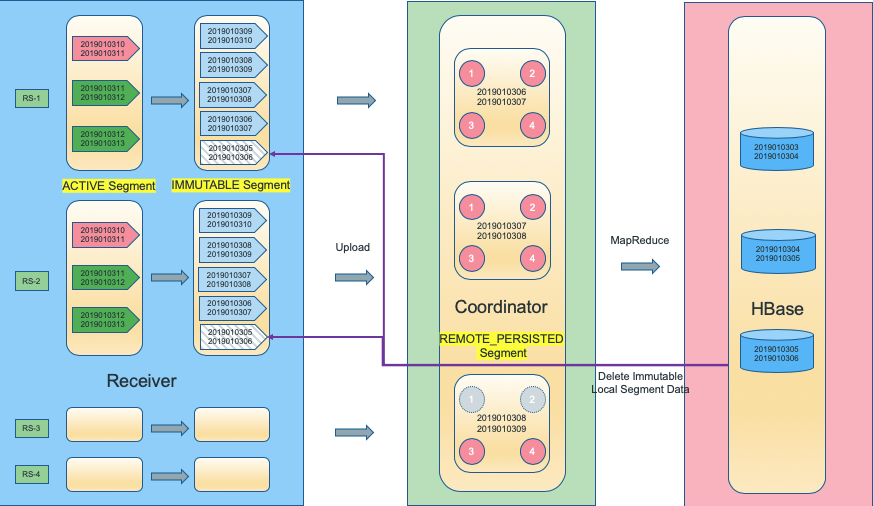
- Receiver represented by the blue area on the left
- Coordinator in the middle of the green area
- The red part on the right indicates HBase
- The flow of data is from left to right
The segments in the Active queue and Immutable queue are controlled by Receiver, the icon of Segment is a pentagon. Each pentagon represents part of the Segment data, because a Replica Set is usually only responsible for a part of the partition of Kafka topic. Conversions from Active to Immutable are controlled by Segment Duration and Segment Window.
When the Segment status changes to Immutable, and Retention Policy is FullBuild, the local columnar data file of the Segment will be queued for upload to HDFS. After finished, the status changes to RemotePersisted.
RemotePersisted segment queue is managed by the Coordinator. The segment icon is a rounded square. Each red circle inside indicates that one Replica Set has uploaded the Segment data file to HDFS. Each gray circle indicates one Replica Set has not completed the segment data upload. So, a rounded square with some gray circle indicates that the Segment cannot be built because the data on HDFS is not complete(data from some partitions are not uploaded).
When all the data files of a Segment (from all Replica Set) have been uploaded, the Segment build job(Mapreduce) is ready to triggered, Coordinator will be submit MR job to Resource Manager.
Once the MR job is finished and the Segment successfully enters HBase, the Coordinator notifies the relevant Receiver to delete the local data(local segment cache), and clears the data stored in the HDFS, set the status of the HBase Segment to READY.
In receiver side, if the number of segments of Immutable and RemotePersisted in the Cube under single Receiver is too large (above kylin.stream.immutable.segments.max.num), the kafka consumer will be paused until the number of Immutable/RemotePersisted is below that threshold.
1.9 Building Process Analysis of Real-time OLAP
Depending on the value of the Retention Policy, when set to Full Build, the Immutable segment will be uploaded to HDFS. When all Replica Sets are uploaded, the Coordinator will build cube and convert the segment cache uploaded to HDFS to HFile by MapReduce.
When Retention Policy set to Purge, the local segment will be deleted periodically, without uploading and building actions.
Building steps
- Merge dictionary
- Convert to base cuboid from columnar data file
- Using InMem Cubing to build segment
1.10 Query Process Analysis of Real-time OLAP
For the SQL statement submitted by the user, whether the history part and real-time part need to be considered is determined by the timestamp partition column.
1. The query result for the historical part comes from all HBase segments in Ready state. Kylin will also records the End time of the latest HBase segment.
2. The query result for the real-time part comes from the Receiver cluster, and the time condition is limited to the Segment which later than the End time of the latest HBase segment.
Receiver under the same Replica Set may have inconsistent ingest rate. In order to avoid inconsistent query results, for one cube, a fixed Receiver will used to answer query request as much as possible. Unless the preferred Receiver is inaccessible, other Receivers will be queried.
1.11 Rebalance/Reassign Process Analysis
Introduction
In order to cope with the rapid increase of Kafka’s message volume, or in other case the Receiver need to go offline, the assignment of Replica Set and the Kafka topic need to be re-adjusted, to make the entire Receiver cluster in a load-balanced state. For such reason, you need the Reassign action.
By the Reassign action, Kylin will stop the ingest/consume of the Receiver that belongs to replica set which need to be removed, and hand over kafka partition that it was responsible formerly to the new Replica Set. This process is done by the Coordinator and the process does not require data movement. The time consuming of the whole process depends on the number of nodes involved in Reassign, which is usually completed in a few seconds.
It should be noted that the Receiver which was removed must not be killed immediately after Reassign action completed. The reason is the data cannot be guaranteed to uploaded to HDFS successfully, and the removed Replica Set is also required for query request.
Reassign Step
Reassign is a process from CurrentAssignment to NewAssignment. The entire Reassign action is a distributed transaction, which can be divided into four steps. If one step fails, the automatic rollback operation will be performed.
- StopAndSync Stop spending and syncing Offset
- Stop the consumption of all Receiver of CurrentAssignment, and each Receiver reports partition offset to Coordinator
- Coordinator merges the offset of each Partition, retains the largest, notifies Receiver to consume to the unified(largest) offset and stop consumption again
- AssignAndStart
- AssignNew sends an assign request to all Receivers of NewAssignment, updating their Assignment
- StartNew sends a startConsumer request to all Receivers of NewAssignment, asking them to start the Consumer based on the Assignment from the previous step
- ImmutableRemoved sends an ImmutableCube request to all Receiver which the removed Replica Set belongs, requiring them to force all Active Segments converted to Immutable
- Update MetaData updates the metadata and logs NewAssignment + RemovedAssignment to the metadata (removed ReplicaSet will still accept the query request after Reassign completes)
If a Replica Set does not change the assignment during the Reassign action, all steps are skipped.
Reassign action will add Removed Replica Set to NewAssignment, but list of partition is empty(see code below).
private CubeAssignment reassignCubeImpl(String cubeName, CubeAssignment preAssignments,
CubeAssignment newAssignments) {
Logger.info("start cube reBalance, cube:{}, previous assignments:{}, new assignments:{}", cubeName,
preAssignments, newAssignments);
If (newAssignments.equals(preAssignments)) {
Logger.info("the new assignment is the same as the previous assignment, do nothing for this reassignment");
Return newAssignments;
}
CubeInstance cubeInstance = CubeManager.getInstance(KylinConfig.getInstanceFromEnv()).getCube(cubeName);
doReassign(cubeInstance, preAssignments, newAssignments);
MapDifference<Integer, List<Partition>> assignDiff = Maps.difference(preAssignments.getAssignments(),
newAssignments.getAssignments());
// add empty partitions to the removed replica sets, means that there's still data in the replica set, but no new data will be consumed.
Map<Integer, List<Partition>> removedAssign = assignDiff.entriesOnlyOnLeft();
For (Integer removedReplicaSet : removedAssign.keySet()) {
newAssignments.addAssignment(removedReplicaSet, Lists.<Partition> newArrayList());
}
streamMetadataStore.saveNewCubeAssignment(newAssignments);
AssignmentsCache.getInstance().clearCubeCache(cubeName);
Return newAssignments;
}When the Segments of the removed Replica Set are all uploaded to HDFS and finished building into HBase, the Assignment of these empty partition list will be cleared.
// for the assignment that doesn't have partitions, check if there is is local segments exist
if (assignments.getPartitionsByReplicaSetID(replicaSetID).isEmpty()) {
Logger.info(
"no partition is assign to the replicaSet:{}, check whether there are local segments on the rs.",
replicaSetID);
Node leader = rs.getLeader();
Try {
ReceiverCubeStats receiverCubeStats = receiverAdminClient.getReceiverCubeStats(leader, cubeName);
Set<String> segments = receiverCubeStats.getSegmentStatsMap().keySet();
If (segments.isEmpty()) {
Logger.info("no local segments exist for replicaSet:{}, cube:{}, update assignments.",
replicaSetID, cubeName);
assignments.removeAssignment(replicaSetID);
streamMetadataStore.saveNewCubeAssignment(assignments);
}
} catch (IOException e) {
Logger.error("error when get receiver cube stats from:" + leader, e);
}
}Figure of reassign
As shown in the figure below, before the Reassign action occurred, the cube was consumed by three Replica Sets, namely RS-0, RS-2, and RS-3(says every replica set has two nodes), and the consumption pressure of each Replica Set was uneven.
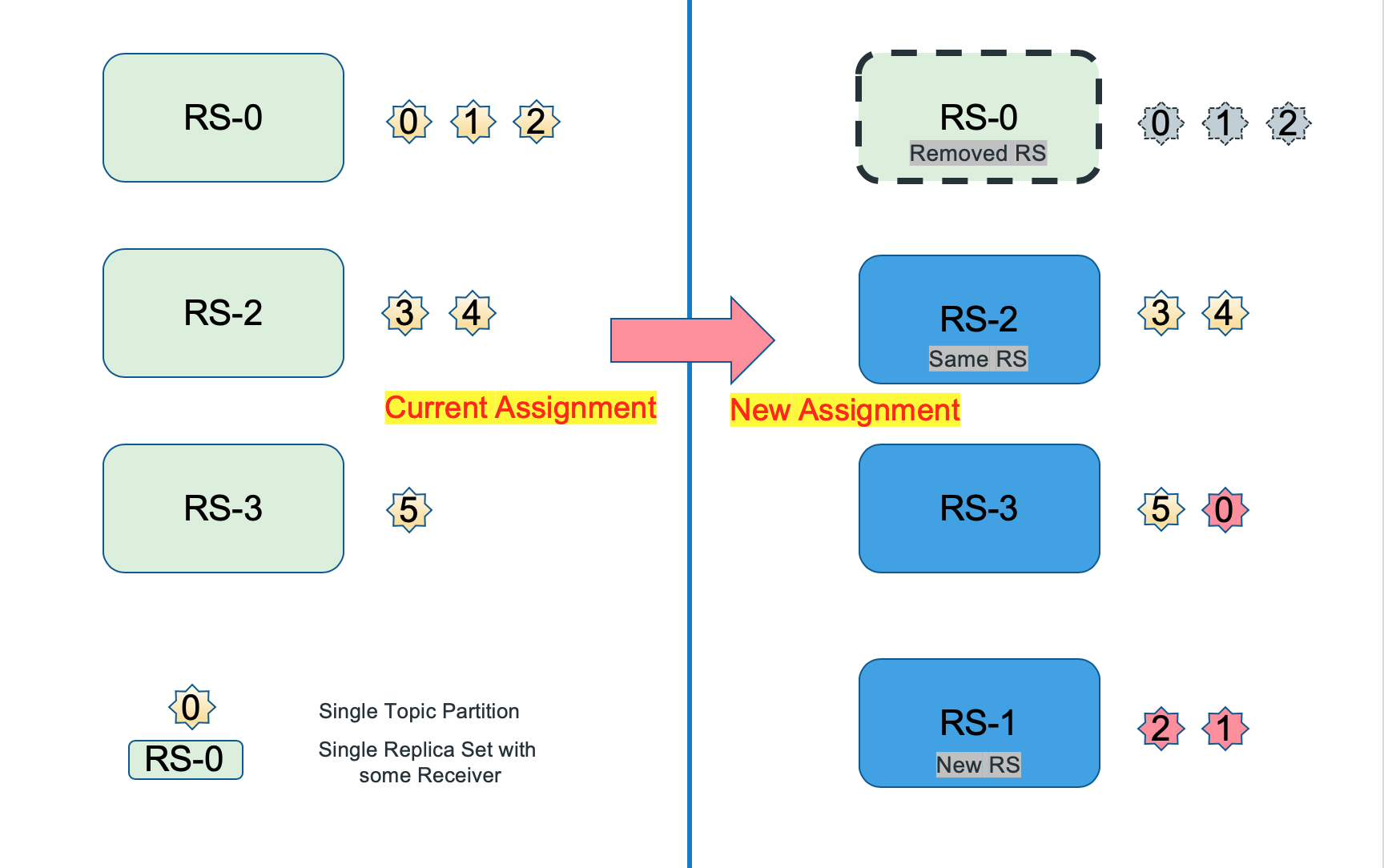
Now for some reason, RS-0 need be offline and RS-1 is added. The Partition responsible for RS-0 needs to be handed over to other Replica Sets. Here, partition-0 is handed over to RS-3, and partition-1 and partition-2 are handed over to RS-1.
RS-0 no longer consumes data after the end of Reassign action, we call it Removed RS.
RS-2 did not change the allocation relationship at all in the Reassign action, which we call Same RS.
RS-1 is be added in the Reassign action, which we call New RS.
- CurrentAssigment
{
"rs-0":[
{
"partition_id":0
},
{
"partition_id":1
},
{
"partition_id":2
}
],
"rs-2":[
{
"partition_id":3
},
{
"partition_id":4
}
],
"rs-3":[
{
"partition_id":5
}
]
}- NewAssignment
{
"rs-1":[
{
"partition_id":1
},
{
"partition_id":2
}
],
"rs-2":[
{
"partition_id":3
},
{
"partition_id":4
}
],
"rs-3":[
{
"partition_id":5
},
{
"partition_id":0
}
]
}Specific steps are as follows
- StopAndSync
In this step, we stop the consumption behavior of all RS contained in CurrentAssigment, but skip Same RS, which isRS-2. - AssignAndStart
In this step, we issue the Assign and StartConsumer requests to all RS contained in NewAssignment, and also skip Same RS,RS-2. - ImmutableRemoved
In this step, we send a mandatory Immutable request to Removed RS, and Removed RS will upload the part of the data it is responsible for to HDFS as soon as possible. - Update MetaData
In this step, the Coordinator will update the metadata and write NewAssignment plus Removed RS as the real NewAssignment to the Metadata.
Before the Removed RS completes the upload and the relevant Segment is successfully built into HBase, the query request is sent to RS-0 to RS-3.
For a more detailed description, read the code source code
To be continued.