
How Cisco's Big Data Team Improved the High Concurrent Throughput of Apache Kylin by 5x
Background
As part of the development group of Cisco’s Big Data team, one of our responsibilities is to provide BI reports to our stakeholders. Stakeholders rely on the reporting system to check the usage of Cisco’s business offerings. These reports are also used as a reference for billing, so they are critical to our stakeholders and the business overall.
The raw data for these reports is sourced across multiple tables in our Oracle database. The monthly data volume for one table is in the billions, and if a customer wants to run a report for one year, at least one billion to two billion rows of data need to be aggregated or processed through other operations. Additionally, all results need to be provided in a short amount of time. In the course of our research, we discovered Apache Kylin, a distributed preprocessing engine for massive datasets based on pre-calculation, which enables you to query those massive datasets at sub-second latency.
With the simulation test using our production data, we found that Kylin was ideal for our needs and was indeed capable of providing aggregated results on one billion rows of data in one second. However, we still needed to undergo additional tests for another use case. For one stakeholder, we provide 15 charts displayed on a single page. The BI system will send REST API requests to Kylin to query the data for each chart asynchronously. Based on the production data volume, if there are 20 stakeholders viewing the report on one node, they will trigger 15*20 = 300 requests. The high concurrent query performance of Kylin is what we needed to test here.
The Testing Stage
Precondition: To reduce the impact from network cost, we deployed the testing tools in the same network environment with Kylin. Meanwhile, we turned off the query cache for Kylin to make sure that each request was executed on the bottom layer.
Testing Tools: Aside from our traditional testing tool, Apache Jmeter, we also used another open source tool: Gatlin (https://gatling.io/) to test the same case. We excluded the impact from the tools.
Testing Strategy: We simulated user requests of different sizes by increasing the number of concurrent threads, tracking the average response in 60 seconds, finding the bottleneck for Kylin query responses, and observing the maximum response time and success rate.
Testing Results:
| Thread | Handled Queries (in 60 seconds) | Handled Queries (per second) | Mean Response Time (ms) |
|---|---|---|---|
| 1 | 773 | 13 | 77 |
| 15 | 3245 | 54 | 279 |
| 25 | 3844 | 64 | 390 |
| 50 | 4912 | 82 | 612 |
| 75 | 5405 | 90 | 841 |
| 100 | 5436 | 91 | 1108 |
| 150 | 5434 | 91 | 1688 |
Resulting in the line chart as follows:
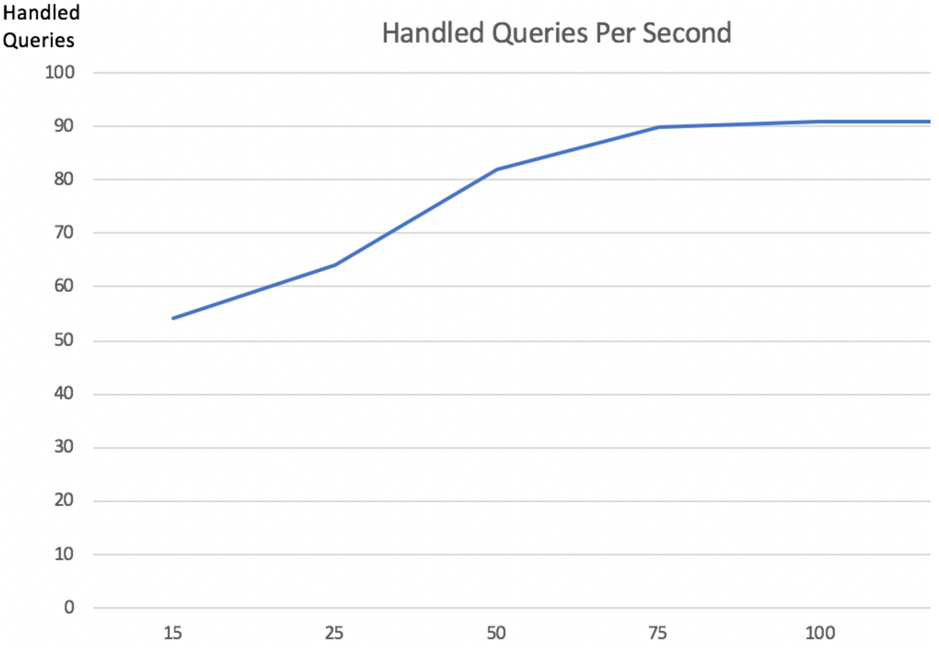
Finding: When the number of concurrent threads reach 75, executed queries per second reach a peak of 90. The number does not become better even as we continue to increase the threads. 90 concurrent query responses in one second only allows 90/15 = 6 users to view a report at the same time. Even when we extend the Kylin query nodes to 3, query capability with 18 users per second is far behind our business demands.
Root Cause Analysis
After reading and analyzing the query engine code of Kylin, we learned that Kylin’s query performs parallel filtering and calculation in HBase’s region server by launching HBase Coprocessor. Based on this information, we checked the resource usage of the HBase cluster. The count of RPC Tasks processed on the region server did not increase linearly with the number of Kylin query requests when high concurrent queries occured. We concluded that there was a thread block on the Kylin side.
We used Flame graph and JProfile to collect and analyze data from the Kylin query node and could not find the root cause. Then we tried to catch a thread snapshot of Kylin with Jstack. Analyzing the Jstack log, we discovered the root cause of the bottleneck causing this concurrent query issue. The example is as follows (Kylin version 2.5.0):
One thread is locked at sun.misc.URLClassPath.getNextLoader. TID is 0x000000048007a180:
"Query e9c44a2d-6226-ff3b-f984-ce8489107d79-3425" #3425 daemon prio=5 os_prio=0 tid=0x000000000472b000 nid=0x1433 waiting ]
java.lang.Thread.State: BLOCKED (on object monitor)
at sun.misc.URLClassPath.getNextLoader(URLClassPath.java:469)
- locked <0x000000048007a180> (a sun.misc.URLClassPath)
at sun.misc.URLClassPath.findResource(URLClassPath.java:214)
at java.net.URLClassLoader$2.run(URLClassLoader.java:569)
at java.net.URLClassLoader$2.run(URLClassLoader.java:567)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findResource(URLClassLoader.java:566)
at java.lang.ClassLoader.getResource(ClassLoader.java:1096)
at java.lang.ClassLoader.getResource(ClassLoader.java:1091)
at org.apache.catalina.loader.WebappClassLoaderBase.getResource(WebappClassLoaderBase.java:1666)
at org.apache.kylin.common.KylinConfig.buildSiteOrderedProps(KylinConfig.java:338)
43 threads were waiting to lock <0x000000048007a180> at the same time:
"Query f1f0bbec-a3f7-04b2-1ac6-fd3e03a0232d-4002" #4002 daemon prio=5 os_prio=0 tid=0x00007f27e71e7800 nid=0x1676 waiting ]
java.lang.Thread.State: BLOCKED (on object monitor)
at sun.misc.URLClassPath.getNextLoader(URLClassPath.java:469)
- waiting to lock <0x000000048007a180> (a sun.misc.URLClassPath)
at sun.misc.URLClassPath.findResource(URLClassPath.java:214)
at java.net.URLClassLoader$2.run(URLClassLoader.java:569)
at java.net.URLClassLoader$2.run(URLClassLoader.java:567)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findResource(URLClassLoader.java:566)
at java.lang.ClassLoader.getResource(ClassLoader.java:1096)
at java.lang.ClassLoader.getResource(ClassLoader.java:1091)
at org.apache.catalina.loader.WebappClassLoaderBase.getResource(WebappClassLoaderBase.java:1666)
at org.apache.kylin.common.KylinConfig.buildSiteOrderedProps(KylinConfig.java:338)
We found that the closest code logic to Kylin was:
org.apache.kylin.common.KylinConfig.buildSiteOrderedProps(KylinConfig.java:338)
Further analyzing the Kylin source code showed we were getting close to the resolution.
Code Analysis
When Kylin query engine builds a request to HBase Coprocessor, it will export Kylin properties (various properties used in Kylin) as Strings. This issue is caused by the relative code logic.
function private static OrderedProperties buildSiteOrderedProps()
- Each thread will getResouce to load “kylin-defaults.properties” (the default properties file that users cannot modify).
// 1. load default configurations from classpath.
// we have a kylin-defaults.properties in kylin/core-common/src/main/resources
URL resource = Thread.currentThread().getContextClassLoader().getResource("kylin-defaults.properties");
Preconditions.checkNotNull(resource);
logger.info("Loading kylin-defaults.properties from {}", resource.getPath());
OrderedProperties orderedProperties = new OrderedProperties();
loadPropertiesFromInputStream(resource.openStream(), orderedProperties);
- Loop 10 times to getResouce for “kylin-defaults” + (i) + “.properties”. Thread LOCKED occurs here.
for (int i = 0; i < 10; i++) {
String fileName = "kylin-defaults" + + ".properties";
URL additionalResource = Thread.currentThread().getContextClassLoader().getResource(fileName);
if (additionalResource != null) {
logger.info("Loading {} from {} ", fileName, additionalResource.getPath());
loadPropertiesFromInputStream(additionalResource.openStream(), orderedProperties);
}
Those logics were introduced in 2017/6/7, with JIRA ID KYLIN-2659 Refactor KylinConfig so that all the default configurations are hidden in kylin-defaults.properties reported by Hongbin Ma.
Issue Fixing
For the first part of the logic, because kylin-defaults.properties is built in kylin-core-common-xxxx.jar, there’s no need to getResource for it every time. We moved this logic to getInstanceFromEnv(). This logic gets called only once when service starts.
We found one regression issue when fixing this bug. One class, CubeVisitService, is a Coprocessor. It will use KylinConfig as util class to generate KylinConfig object. It’s dangerous to induce any logic to load properties. Due to this, there is no Kylin.properties file in Coprocessor.
buildDefaultOrderedProperties();
For the second part, this design should be future-proof and allow users to define 10 default properties (and override with each other), but after a year and a half, this logic seemed to never be used. However, to reduce risk, we kept this logic because it only gets called once during service start up which resulted in an insignificant waste of additional time.
Performance Testing After Bug Fixes
Based on the same data volume and testing environment, results were as follows:
| Thread | Handled Queries (in 60 seconds) | Handled Queries (per second) | Mean Response Time (ms) |
|---|---|---|---|
| 1 | 2451 | 41 | 12 |
| 15 | 12422 | 207 | 37 |
| 25 | 15600 | 260 | 56 |
| 50 | 18481 | 308 | 129 |
| 75 | 21055 | 351 | 136 |
| 100 | 24036 | 400 | 251 |
| 150 | 28014 | 467 | 277 |
And the resulting line chart:
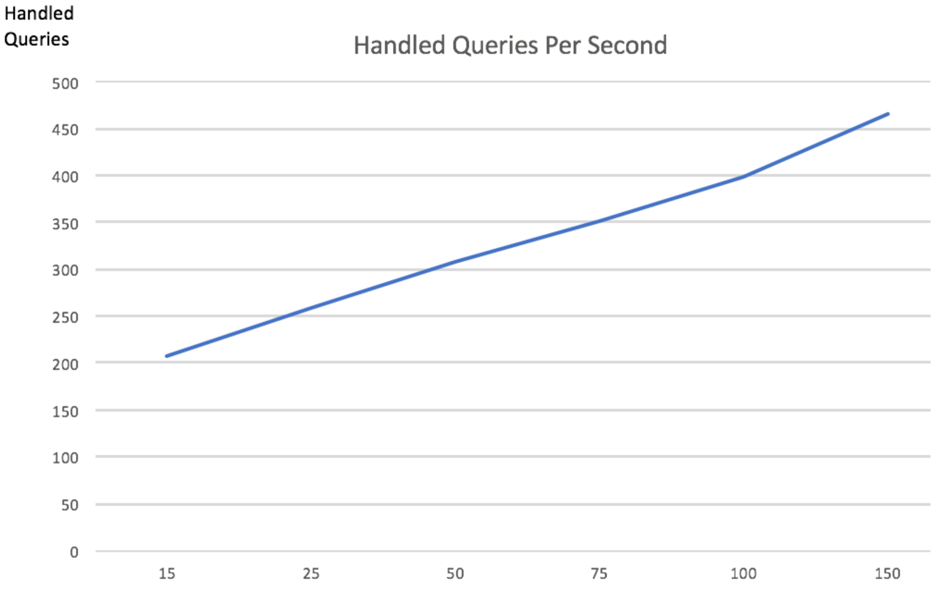
When the concurrent threads reached 150, Kylin processed 467 requests per second. The concurrent query capability increased by five times with linear growth . It could be concluded then that the bottleneck was eliminated . We didn’t increase the concurrent threads due to the Kylin query engine’s settings for cluster load balancing which meant that increasing the concurrent connections on a single node increased the workload on the Tomcat server (Max connection is 150 in Kylin by default). The thread blocking issue disappeared after re-collecting and analyzing the Jstack log.
After the fix, each Kylin node could now handle requests for 467/15 = 31 users, which meets our business requirement. Additionally, Kylin’s concurrent query capability can be further improved by several times once we enable query cache, so it is more than sufficient to fulfill our needs.
Summary
Apache Kylin lets you query massive datasets at sub-second latency, thanks to the pre-calculation design of cubes, the optimization of Apache Calcite operator in queries, and also the introduction of “Prepared Statement Cache” to reduce the cost of Calcite SQL parses. Query performance optimization is not easy. We need to pay more attention to impacts on the Kylin query engine when new features are introduced or bugs are fixed, since even a minor code change could spell disaster. Issues like these in high concurrency scenarios can often be hard to reproduce and analyze.
Lastly, query performance testing should not be limited to a single or small set of queries. High concurrecy performance testing should take place considering actual business requirements. For enterprise reporting systems, 3 seconds is the user tolerance limit for new page loading, which includes page rendering and network consumption. Ultimately, the backend data service should provide a response within 1 second. This is indeed a big challenge in a business scenario with big data sets. Fortunately, Kylin easily meets this requirement.
This issue has already been submitted on JIRA as KYLIN-3672, and released in Kylin v2.5.2. Thanks to Shaofeng Shi of Kyligence Inc. for help.
【1】https://issues.apache.org/jira/browse/KYLIN-3672
Author Zongwie Li as a Cisco engineer and a team member in the company’s Big Data architecture team, currently responsible for OLAP platform construction and customer business reporting systems.