
Introduce data source SDK
Data source SDK
Apache Kylin has already supported several data sources like Amazon Redshift, SQL Server through JDBC. But we found that it takes much efforts to develop an implementation to a new source engine, like supporting metadata sync, cube build and query pushdown. It’s mainly because the SQL dialects and jdbc implementations between source engines are quite different.
So since 2.6.0, Kylin provides a new data source SDK, which provides APIs to help developers handle these dialect differences and easily implement a new data source through JDBC.
With this SDK, users can achieve followings from a JDBC source:
- Synchronize metadata and data from JDBC source
- Build cube from JDBC source
- Query pushdown to JDBC source engine when cube is unmatched
Structure
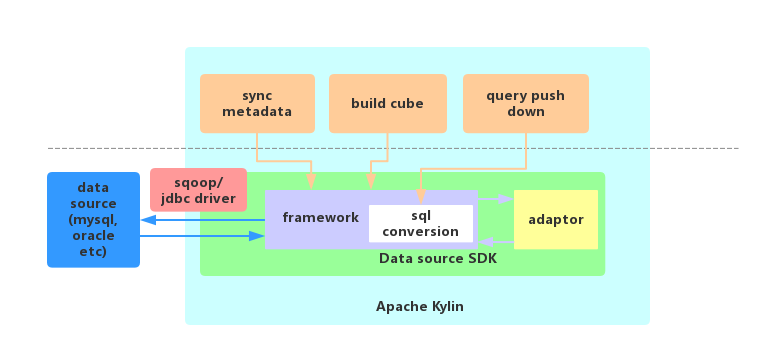
When users want to synchronize metadata or get data from data source, the request pass through the framework, and the framework find the adaptor what has an API for metadata and data.
To avoid having complex adaptors, when having a push-down query, framework provides sql conversions from ansi sql to target data source dialect(includes sql functions and sql types), and adaptor just provide a function fixSql to fix the sql after conversion.
How to develop
Please follow this doc