
Streaming cubing (Prototype)
One of the most important features in v1.5 is streaming cubing which enables OLAP analysis on streaming data. Streaming cubing delivers faster insights on the data to help more promptly business decisions. Even though there are already many real time analysis tools in open source community, Kylin Streaming cubing still differs from them in multiple angles:
Firstly, Kylin Streaming Cubing aligns with Kylin traditional cubing to provided unified, ANSI SQL interface. Actually Kylin Streaming shares the storage engine and query engine with traditional Kylin cubes, so in theory all of the optimization techniques to save storage and speed up query performance can also be applied on streaming cubes. Besides, all the supported aggregations/filters/UDFs still work for streaming cubes. By unifying the storage engine and query engine we also get freed from double amount of maintaince work.
Secondly, Kylin Streaming Cubing does not require large amount of memory to store real time data, nor does it attempts to provide truly “real time” analysis. By our customer survey we found that minutes of visualization latency is acceptable for OLAP analysts. So our streaming cubing adopts the micro batch approach. Incoming streaming data are partitioned into different time windows and we build a micro batch for each time window. The cube output for each micro batch is directly saved to HBase. The query engine goes to HBase for data retrieving instead of the data ingestion server. The benefit of such design is that we don’t have to maintain large amount of in-memory index which could easily require tens of gigabytes of memory. In the future Kylin might need to consider truly “real time” support, too.
Thirdly, Kylin Streaming Cubing data will be persistent and gradually be converted to traditional cubes, thus customers can still query “cold data” without any compromise on performance. As discussed above the output of streaming cubing is directly saved to HBase as a new segment. The traditional job engine will be notified of the new segment and take over to schedule merge jobs when then segments accumulates. Day after day the segments of the streaming cube got merged and become a very large traditional cube.
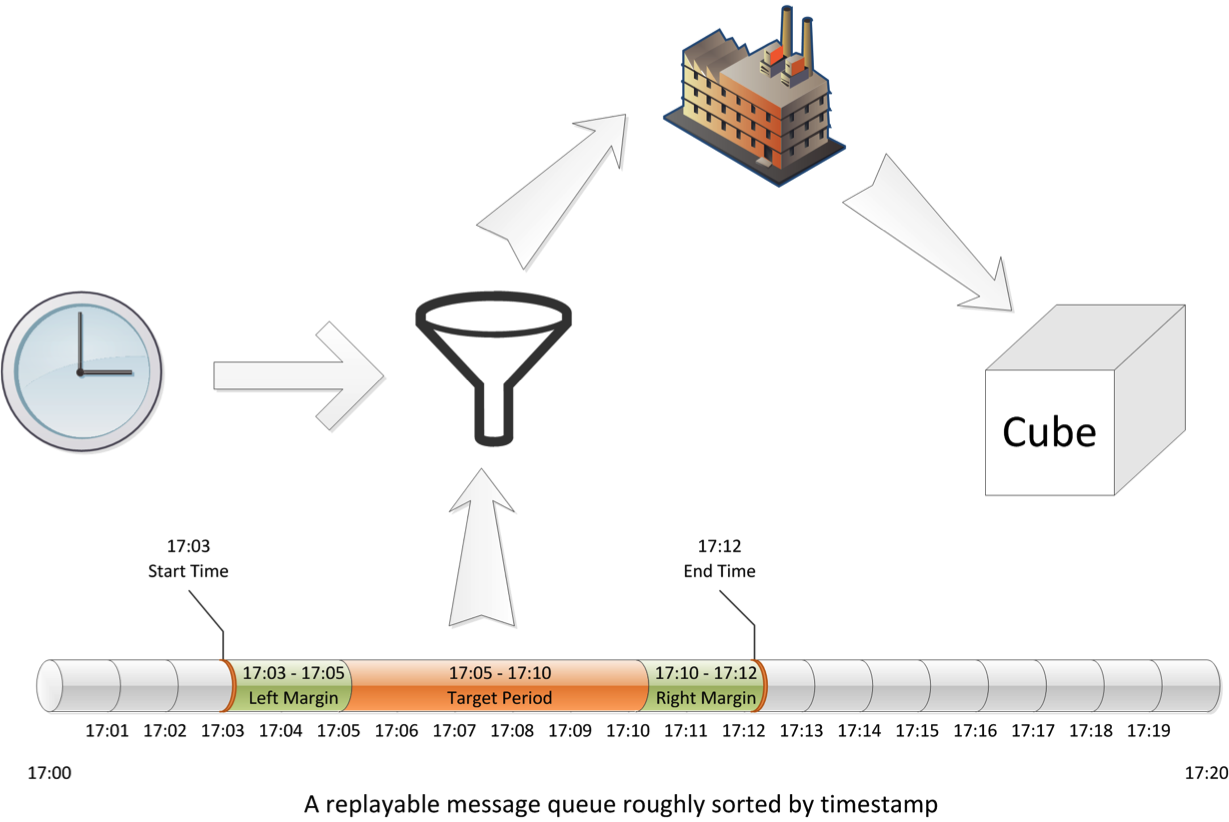
With the major difference in mind we will introduce the modules for Kylin Streaming cubing. Kylin Streaming cubing consist of three major parts:
- Streaming Input to retrieve data from a replayable data queue (currently it is Kafka) within given time window. Streaming Input is also responsible for primary data cleaning and normalization. By default Kylin Streaming provides a default implementation to parse the messages from the source queue. Customers can choose to configure the parser or provide a brand new one based on their requirements.
- Streaming Batch Ingestion to ingest the incoming data batch and transform it into a micro cube. Thanks to the latest Kylin In-memory cubing technology, this step is now times faster and space-saving than previous. The micro cube is directly saved to HBase.
- Job Scheduling Module to trigger Streaming Batch Ingestion. Kylin does not put too much efforts in job scheduling, streaming cubing is not a exception. Currently we provided a simple implementation based on Linux Crontab.
We’ll publish more detailed documents on how to use Kylin Streaming soon. Please stay tuned.