
Fast Cubing Algorithm in Apache Kylin: Concept
This article is the first post of a series document that introducing the fast cubing algorithm in Apache Kylin; The new algorithm will be released in the future release; Now it is under internal testing and pilot; All the source code has been published in Kylin’s Git repository https://github.com/apache/kylin/ on 0.8 branch.
By Layer Cubing Algorithm
Before introduce the fast cubing, I’d like to make a brief introduction on the as-is cubing algorithm, which is called “by layer cubing”;
As its name indicates, a full cube is calculated by layer: N-dimension, N-1 dimension, N-2 dimension, … until 0 dimension; Each layer’s calculation is based on its parent layer (except the first, which base on source data); So this algorithm need N rounds of MapReduce running in sequence;
In the MapReduce, the key is the composite of the dimensions, the value is the composite of the measures; When the mapper reads a key-value pair, it calculates its possible child cuboids; for each child cuboid, remove 1 dimension from the key, and then output the new key and value to the reducer;
The reducer gets the values grouped by key; it aggregates the measures, and then output to HDFS; one layer’s MR is finished;
When all layers are finished, the cube is calculated;
Figure 1 describes the flow:
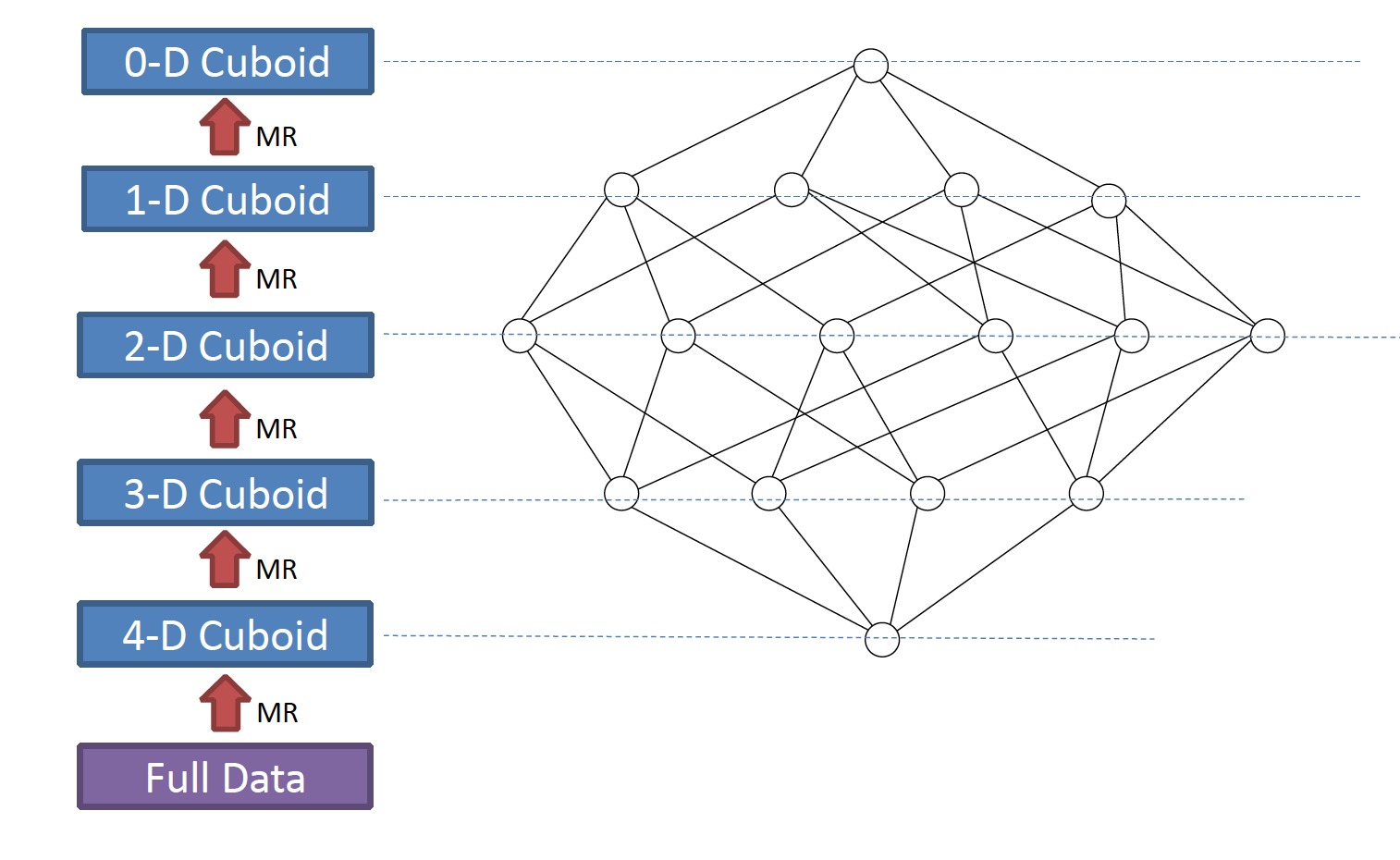
Figure 1: By layer cubing
Advantage
- This algorithm is clear as it mostly leverage the capability of Hadoop MapReduce; The sorting, grouping and shuffling are all taken care by MapReduce, developer just focus on the cubing logic;
- Benefiting from Hadoop’s maturity, this algorithm is very stable; In our experience there is seldom case that the mapper or reducer could fail; Even if your Hadoop cluster is small or is busy, it can finish in the end;
Disadvantage
- If the cube has many dimensions, it need the same number of MR jobs; As each Hadoop job scheduling need extra resource, the overhead cost to Hadoop is considerable;
- This algorithm causes too much shuffling to Hadoop; The mapper doesn’t do aggregation, all the records that having same dimension values in next layer will be omitted to Hadoop, and then aggregated by combiner and reducer;
- Many reads/writes on HDFS: each layer’s cubing need write its output to HDFS for next layer MR to consume; In the end, Kylin need another round MR to convert these output files to HBase HFile for bulk load; These jobs generates many intermediate files in HDFS;
- All in all: the performance is not good, especially when the cube has many dimensions;
Fast Cubing Algorithm
The fast cubing algorithm is also called “by segment cubing”; The core idea is, each mapper calculates the feed data block into a small cube segment (with all cuboids), and then output all key/values to reducer; The reducer aggregates them into one big cube segment, finishing the cubing; Figure 2 illustrates the flow;
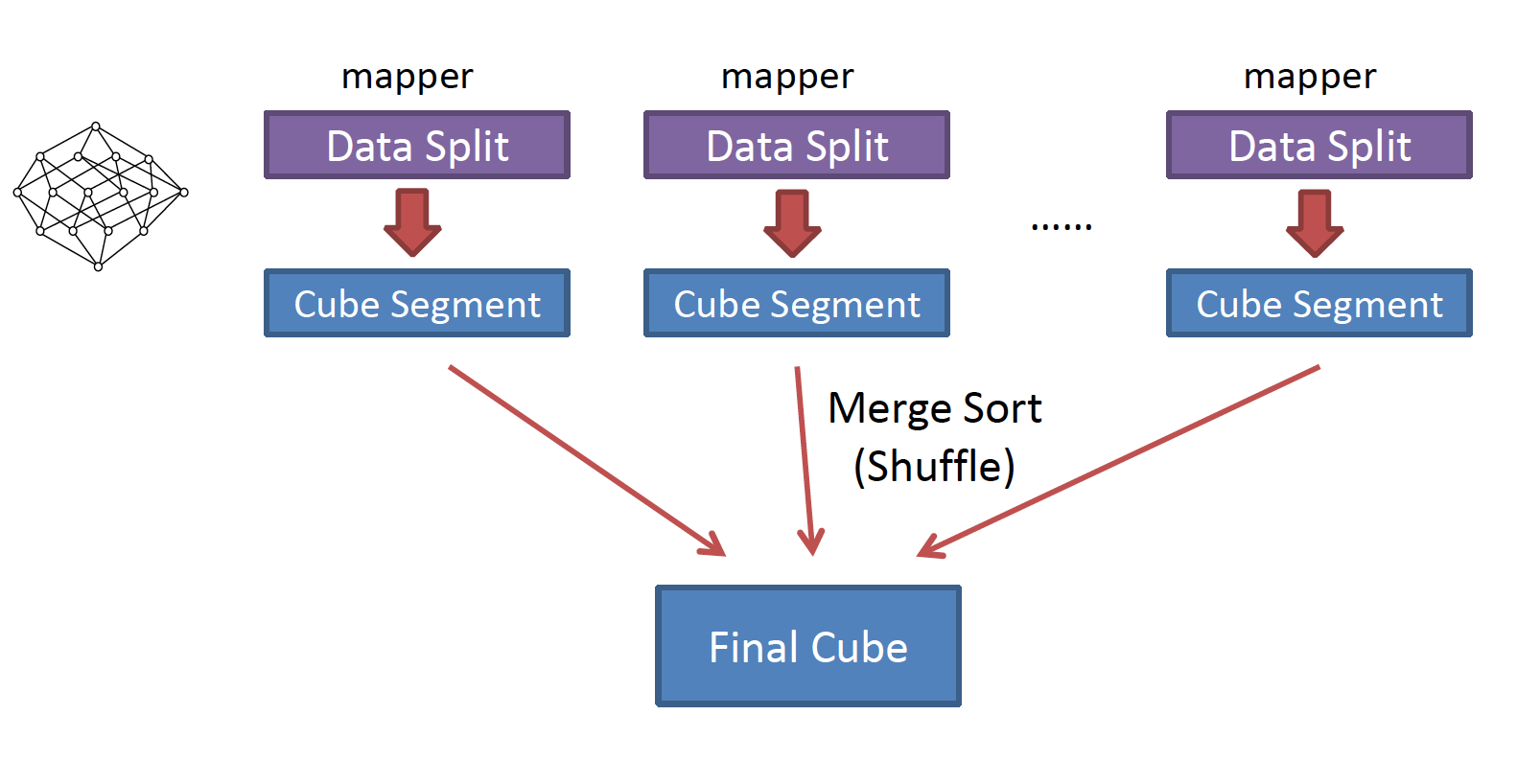
Figure 2: By segment cubing
Pre-aggregation in Mapper
Compared with the origin algorithm, the fast cubing has two main differences:
- The mapper will do pre-aggregation, this will reduce the number of records that the mapper output to Hadoop, and also reduce the number that reducer need to aggregate;
- One round MR can calculate all cuboids;
Let take an example: a cube has 4 dimensions: A, B, C, D; Each mapper has 1 million source records to process; The column cardinality in the mapper is Car(A), Car(B), Car(C) and Car(D);
-
When aggregate the source records to base cuboid (1111), with the old “by layer” algorithm, the mapper will output 1 million records to Hadoop; With the fast cubing algorithm, after the pre-aggregation, it only outputs the number of [distinct A, B, C, D] records to Hadoop, which is certainly smaller than source data; In a normal case, it can be 1/10 to 1/1000 of the source records size;
-
When aggregate from parent to a child cuboid, say from base cuboid (1111) to 3-dimension cuboid 0111, the dimension A will be aggregated; We assume the dimension A is independent with other dimensions, after aggregation, the cuboid 0111’s size will be about 1/Card(A) of the base cuboid; So the output will be reduced to 1/Card(A) of the original one in this step.
Totally, assume the average cardinality of the dimensions is Card(N), the records that written from mapper to reducer can be reduced to 1/Card(N) of origin size; The less output to Hadoop, the less I/O and computing, the better performance.
Cuboid spanning tree
Inner the mapper, there is another change in the cuboid spanning tree visiting order; In origin cubing, Kylin calculates the cuboids with Broad First Search order; In the fast cubing, it uses Depth First Search order, to reduce the cuboids that need be cached in memory.
Let’s look at the figure 3, which is a full spanning tree of a 4-dimension cube: before 0-Dimenson cuboid “*” be aggregated, cuboid “ABCD”, “BCD”, “CD” and “D” will be cached in memory; As “*” has no child, it will be outputted once be calculated, then comes “D”; After “C” be outputted, “CD” will be outputted as all of its children has finished; The memory for a cuboid can be released once it be outputted; The base cuboid ABCD will be the last one to output.
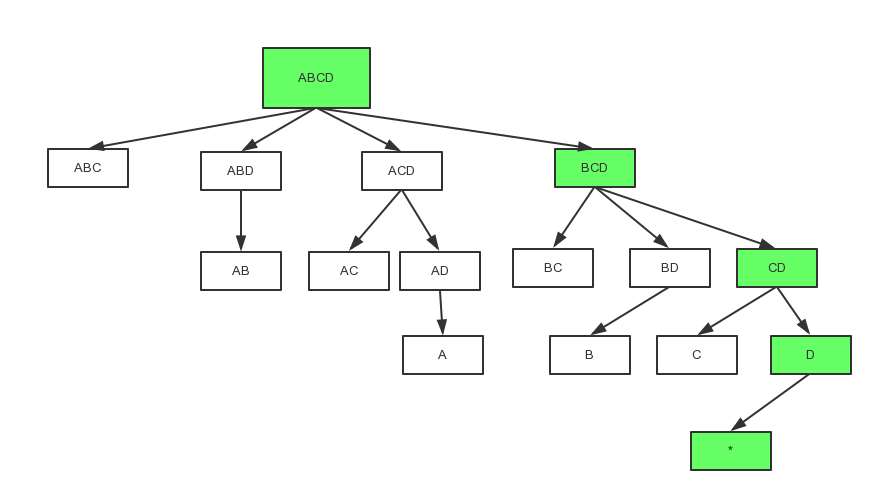
Figure 3: Cuboid spanning tree
With the DFS visiting order, the output from a mapper is fully sorted (except some special cases), as the cuboid ID is at the beginning position of row key, and inner a cuboid the rows are already sorted:
0000
0001[D0]
0001[D1]
....
0010[C0]
0010[C1]
....
0011[C0][D0]
0011[C0][D1]
....
....
1111[A0][B0][C0][D0]
....
Since the outputs from mapper are already sorted, Hadoop’s sort would be more efficient;
Besides, mapper’s pre-aggregation happens in memory, this avoids unnecessary disk and network I/O, and the overhead to Hadoop is reduced;
###OutOfMemory error
During the development phase, we encountered the OutOfMemory error in mappers; this could happen when:
a) The mapper's JVM heap size is small;
b) "Distinct count" measure is used (HyperLogLog is space consuming)
c) The spanning tree is too deep (too many dimensions);
d) The data blog feed to a mapper is too big;
We realized that Kylin couldn’t assume the mappers always have enough memory; The cubing algorithm need be self-adapting to various situations; A lot of efforts were put on optimizing the memory use and spilling data to disk when proactively detects an OutOfMemory error; The result is promising, the OOM error is rare to occur now;
Here let’s do a summary on the fast cubing algorithm;
Advantage
- It is faster than the old method; can reduce 30% to 50% overall building time from our comparison test;
- It produces less work load on Hadoop, and leaves less intermediate files on HDFS;
- The cubing code can be easily reused by other cubing engines like Streaming and Spark;
Disadvantage
- The algorithm is a little complicated; This adds the maintenance effort;
- Although the algorithm can spill data to disk automatically, it still wish the mapper has enough memory to gain best performance; User need more knowledge to tune the cubing; (this can be discussed in detail later)
Other Enhancements in Fast Cubing
Together with the fast cubing algorithm, we also introduced several other enhancements in the cube build flow, like estimating the region splits by sampling, directly outputting HFile, and merging Cube over HBase Table, etc; I’d like to elaborate in the next articles, please keep posted here; If you have interest on Apache Kylin, welcome to visit our home page http://kylin.apache.org/ and subscribe our development mailing list at dev-subscribe@kylin.apache.org